
In our last post, we summarized the thinking behind the data mesh design pattern. In this post (2 of 5), we will review some of the ideas behind data mesh, take a functional look at data mesh and discuss some of the challenges of decentralized enterprise architectures like data mesh. Last we’ll explore how DataOps can be paired with data mesh to mitigate these challenges.
Large, centralized enterprise architectures discourage agility. The centralized architecture consists of various pipelines that ingest, process and serve data. Everyone on the data team works on their specialized part of the larger system, and they rely upon emails, documents and meetings to stay organized. Figure 1 shows the strained lines of communications that cross-functional boundaries. Roles tend to be more specialized on a big team, so there are bottlenecks. With heavyweight processes, it becomes much more bureaucratic to change any part of the architecture. With a steady stream of requests for new data sources and new analytics, the centralized team managing the platform can quickly exceed their capacity to keep up. Customers are on a journey to get insight, and they may not know exactly what they want until they see it. With large systems, it’s much harder to iterate toward a solution that addresses a user’s latent requirements.
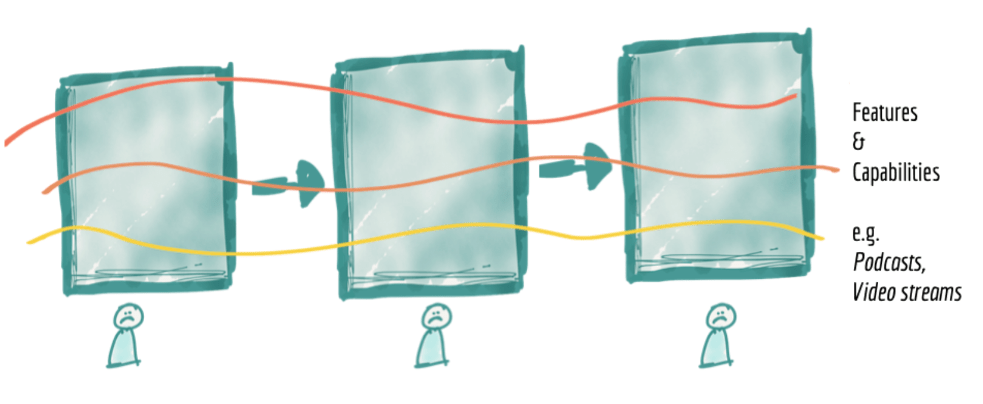
Figure 1: When you make a change to a centralized platform, you need to update each component and coordinate between several different teams. Source: Thoughtworks
Data mesh decouples the subsystem teams from each other. By partitioning the system into pieces, each domain team can work uninterrupted and at their natural iteration cadence. Over time, domain teams attain a much more intimate understanding of their data sources and uses, leading to more effective technical solutions. The data team addresses the backlog of tasks more quickly because task coordination is more straightforward with a smaller team. The data mesh team assumes total lifecycle ownership of the domain. The domain is their internal “product,” and the domain product manager is their empowered mini-CEO – you may have heard the term “product thinking” with respect to a data mesh. Success means excellently serving the needs of internal customers. Team members cover all the roles, so there are more hybrid players enabling more flexibility in responding to surges in demand for a particular skill set. When something goes wrong, the domain team has all the right incentives to iterate on a solution.
Data Mesh Architecture Example
The concept of data mesh, proposed by Zhamak Dehghani, has taken the industry by storm. Below we’ll look at a simple example architecture partitioned into domains to illustrate data mesh.
You may have used a media streaming application such as Spotify or SoundCloud. A streaming service has to handle a variety of activities that logically partition into different areas:
- Artists – onboard, pay, manage, …
- Podcasts – create, release, play, …
- Users – register, manage profiles, manage access, …
A centralized enterprise application would combine all of these functions and services into one monolithic architecture. A data mesh organizes each functional domain as a separate set of services. In figure 2 below, three domains are shown. A dedicated team handles artists, podcasts and users respectively, but each domain depends on data and services from other domains and operational systems. The domains in the figure are shown receiving data from input data ports (IDP) and transmitting data to output data ports (ODP).
The act of onboarding a new artist activates an artist onboarding service that updates the artists domain. When a user plays a podcast (within the podcast domain), it triggers an input into the artist’s domain, which activates the artist payment service. Application scalability improves as each group independently manages its domain. For example, the users domain team could add a new data set or new microservices related to users data with complete autonomy. If you still have difficulty understanding the concept of the data mesh design pattern, please see our recent post “What is a Data Mesh?”
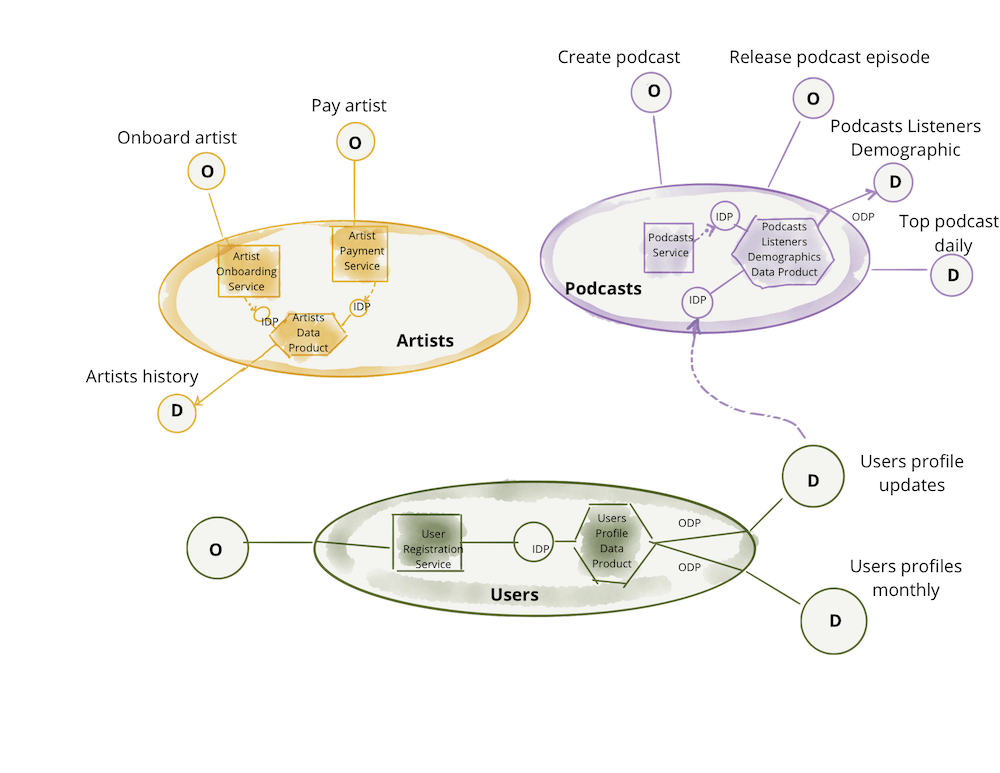
Figure 2: Data mesh organizes the streaming application into artists, podcasts and users domains. Source: Thoughtworks
Challenges Related to Data Mesh
In data analytics, there is a constant tension between centralization and decentralization. Data democratization and self-service analytics empower innovation, but the enterprise must adhere to strict governance standards. We need one version of reality, but over-centralizing analytics creates bottlenecks.
Data mesh leans the enterprise hard in the direction of decentralization. The benefits of granting autonomy to small teams are well established. The domain team develops workflows and practices aligned with user requirements and their own team culture. A group of five to nine people is large enough to vet ideas but not so large as to stifle innovation. The team develops an intimate understanding of their data and its application within the greater data organization. Domains foster a sense of ownership, accountability and an alignment of incentives.
The disadvantages of decentralization are also well known. Greater decentralization raises the overall level of chaos. Decentralization makes it harder to enforce governance, security and other policies. Decentralization may not adequately manage intellectual property. The table below summarizes the advantages and disadvantages of a decentralized organizational structure.
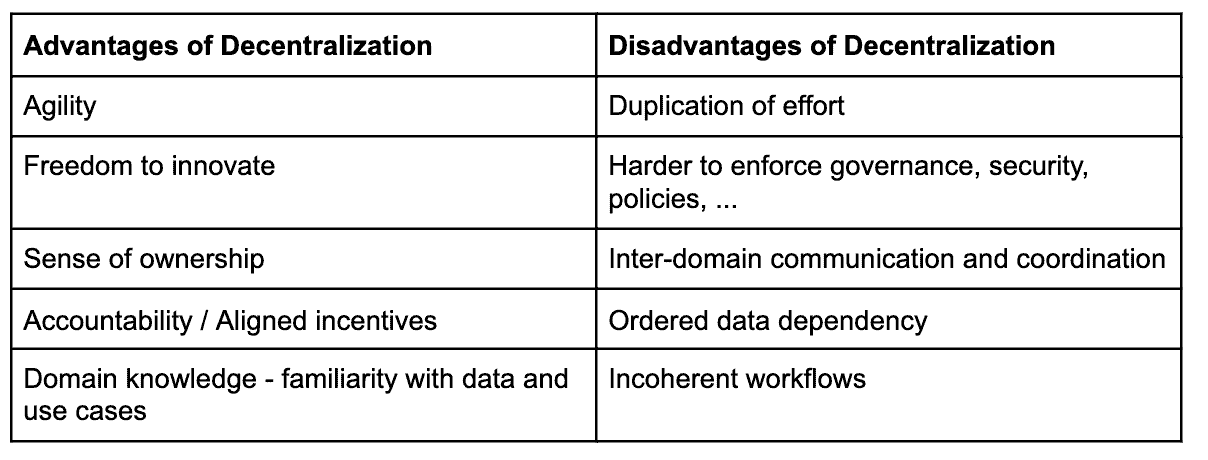
Table 1: Advantages and disadvantages of decentralized architectures
An array of interdependent domains may sound great in theory, but we can say from experience, a decentralized organizational/architectural structure raises a host of issues that must be addressed. For example, managing ordered data dependencies, inter-domain communication, shared infrastructure, and incoherent workflows. Also, decentralized teams tend to duplicate effort, for example, in horizontal infrastructure that cuts across multiple domains. We are not alone in raising these concerns. In her innovative article on data mesh, Zhamak Dehghani mentions:
One of the main concerns of distributing data ownership to the domains is the duplicated effort and skills required to operate the data pipelines technology stack and infrastructure in each domain.
Data mesh is a powerful new idea, but it will not operate free of bottlenecks unless steps are taken to manage the creative chaos that ensues.
The DataKitchen DataOps Platform is expressly built to address the challenges of a decentralized organizational structure/architecture such as a data mesh. The DataKitchen Platform spans toolchains, teams and data centers to incorporate all of an enterprise’s domains into a single DataOps superstructure. Data mesh and DataOps make a great team that enables innovation through decentralization while harmonizing domain activities in a coherent end-to-end pipeline of workflows. Data mesh encourages autonomy, while DataOps handles global orchestration, shared infrastructure, inter-domain dependencies and enables policy enforcement. The infrastructure ingredients required by domains can be unified into a self-service infrastructure-as-a-platform managed using a DataOps superstructure. DataOps is the perfect partner to data mesh.
In our next post, we’ll look at some technical aspects of data mesh so that we can look at a real-world data mesh pharmaceutical example. If you missed any part of this series, you can return to the first post here: “What is a Data Mesh?”





