SMOTE for Imbalanced Classification with Python
Introduction
Imbalanced datasets pose a common challenge for machine learning practitioners in binary classification problems. This scenario frequently arises in practical business applications like fraud detection, spam filtering, rare disease discovery, and hardware fault detection. To address this issue, one popular technique is Synthetic Minority Oversampling Technique (SMOTE). SMOTE is specifically designed to tackle imbalanced datasets by generating synthetic samples for the minority class. This article explores the significance of SMOTE in dealing with class imbalance, focusing on its application in improving the performance of classifier models. By mitigating bias and capturing important features of the minority class, SMOTE contributes to more accurate predictions and better model performance.
This article was published as a part of the Data Science Blogathon.
Table of contents
The Accuracy Paradox
Suppose, you’re working on a health insurance based fraud detection problem. In such problems, we generally observe that in every 100 insurance claims 99 of them are non-fraudulent and 1 is fraudulent. So a binary classifier model need not be a complex model to predict all outcomes as 0 meaning non-fraudulent and achieve a great accuracy of 99%. Clearly, in such cases where class distribution is skewed, the accuracy metric is biased and not preferable.
Dealing with Imbalanced Data
Resampling data is one of the most commonly preferred approaches to deal with an imbalanced dataset. There are broadly two types of methods for this i) Undersampling ii) Oversampling. In most cases, oversampling is preferred over undersampling techniques. The reason being, in undersampling we tend to remove instances from data that may be carrying some important information. In this article, I am specifically covering some special data augmentation oversampling techniques: SMOTE and its related counterparts.
SMOTE: Synthetic Minority Oversampling Technique
SMOTE is an oversampling technique where the synthetic samples are generated for the minority class. This algorithm helps to overcome the overfitting problem posed by random oversampling. It focuses on the feature space to generate new instances with the help of interpolation between the positive instances that lie together.
Working Procedure
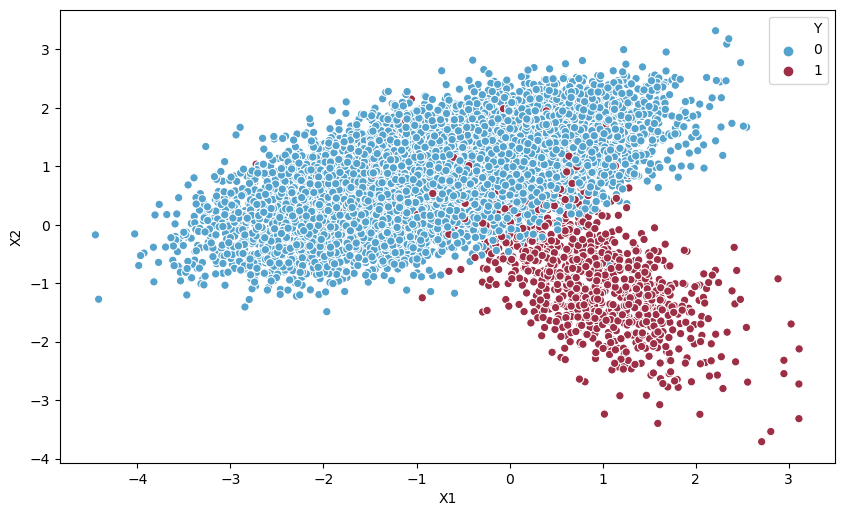
At first the total no. of oversampling observations, N is set up. Generally, it is selected such that the binary class distribution is 1:1. But that could be tuned down based on need. Then the iteration starts by first selecting a positive class instance at random. Next, the KNN’s (by default 5) for that instance is obtained. At last, N of these K instances is chosen to interpolate new synthetic instances. To do that, using any distance metric the difference in distance between the feature vector and its neighbors is calculated. Now, this difference is multiplied by any random value in (0,1] and is added to the previous feature vector. This is pictorially represented below:
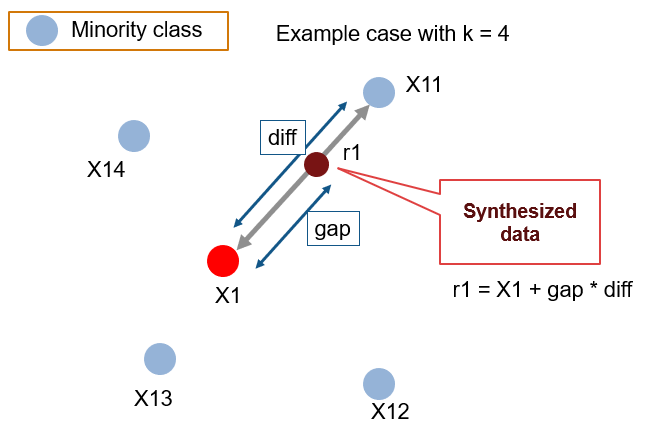
Python Code for SMOTE Algorithm
Though this algorithm is quite useful, it has few drawbacks associated with it.
- The synthetic instances generated are in the same direction i.e. connected by an artificial line its diagonal instances. This in turn complicates the decision surface generated by few classifier algorithms.
- SMOTE tends to create a large no. of noisy data points in feature space.
ADASYN: Adaptive Synthetic Sampling Approach
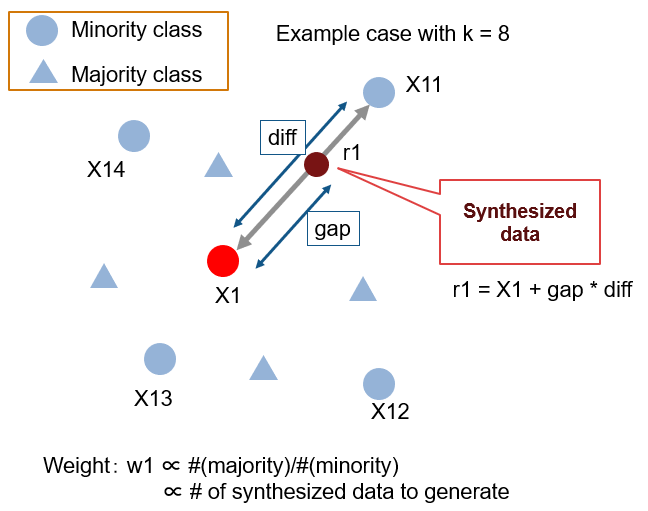
ADASYN is a generalized form of the SMOTE algorithm. This algorithm also aims to oversample the minority class by generating synthetic instances for it. But the difference here is it considers the density distribution, ri which decides the no. of synthetic instances generated for samples which difficult to learn. Due to this, it helps in adaptively changing the decision boundaries based on the samples difficult to learn. This is the major difference compared to SMOTE.
Working Procedure
- From the dataset, the total no. of majority N– and minority N+ are captured respectively. Then we preset the threshold value, dthfor the maximum degree of class imbalance. Total no. of synthetic samples to be generated, G = (N– – N+) x β. Here, β = (N+/ N–).
- For every minority sample xi, KNN’s are obtained using Euclidean distance, and ratio riis calculated as Δi/k and further normalized as rx <= ri / ∑ rᵢ.
- Thereafter, the total synthetic samples for each xi will be, gi= rx x G. Now we iterate from 1 to gi to generate samples the same way as we did in SMOTE.
The below-given diagram represents the above procedure:
Python Code for ADASYN Algorithm
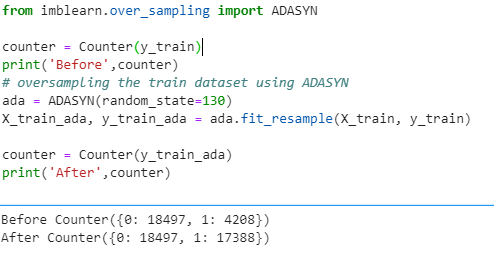
Hybridization: SMOTE + Tomek Links
Hybridization techniques involve combining both undersampling and oversampling techniques. This is done to optimize the performance of classifier models for the samples created as part of these techniques.
SMOTE+TOMEK is such a hybrid technique that aims to clean overlapping data points for each of the classes distributed in sample space. After the oversampling is done by SMOTE, the class clusters may be invading each other’s space. As a result, the classifier model will be overfitting. Now, Tomek links are the opposite class paired samples that are the closest neighbors to each other. Therefore the majority of class observations from these links are removed as it is believed to increase the class separation near the decision boundaries. Now, to get better class clusters, Tomek links are applied to oversampled minority class samples done by SMOTE. Thus instead of removing the observations only from the majority class, we generally remove both the class observations from the Tomek links.
Python Code for the SMOTE + Tomek Algorithm
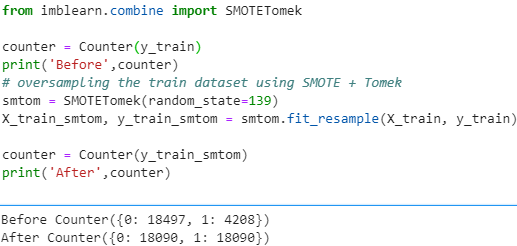
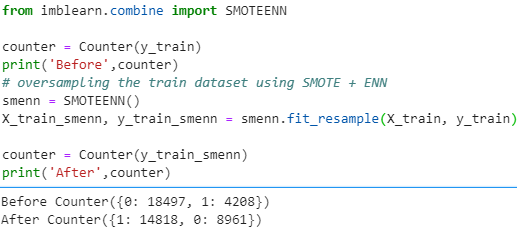
Hybridization: SMOTE + ENN
SMOTE + ENN is another hybrid technique where more no. of observations are removed from the sample space. Here, ENN is yet another undersampling technique where the nearest neighbors of each of the majority class is estimated. If the nearest neighbors misclassify that particular instance of the majority class, then that instance gets deleted.
Integrating this technique with oversampled data done by SMOTE helps in doing extensive data cleaning. Here on misclassification by NN’s samples from both the classes are removed. This results in a more clear and concise class separation.
Python Code for SMOTE + ENN Algorithm
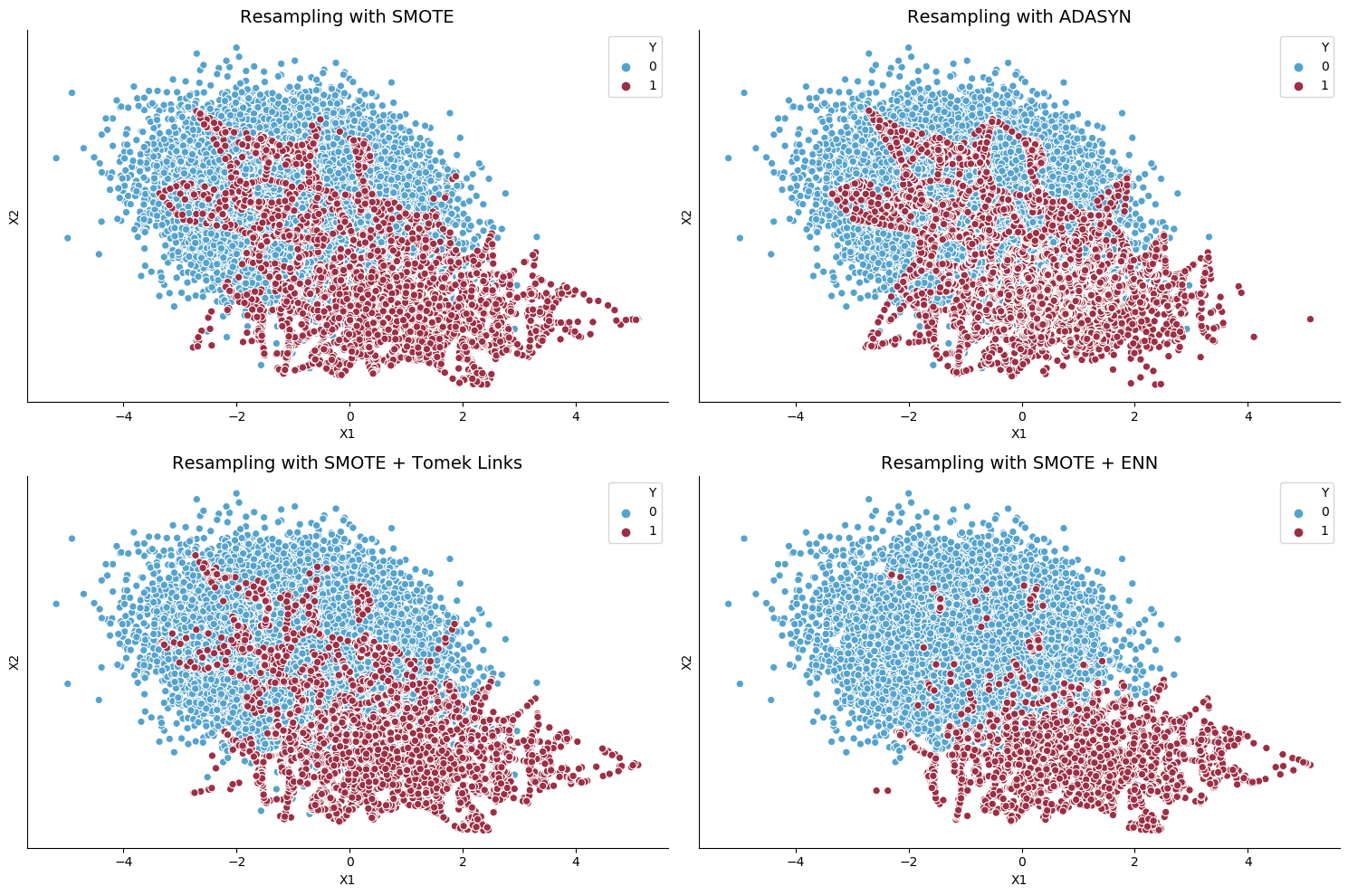
The below-given picture shows how different SMOTE based resampling techniques work out to deal with imbalanced data.
Performance Analysis after Resampling
To understand the effect of oversampling, I will be using a bank customer churn dataset. It is an imbalanced data where the target variable, churn has 81.5% customers not churning and 18.5% customers who have churned.
A comparative analysis was done on the dataset using 3 classifier models: Logistic Regression, Decision Tree, and Random Forest. As discussed earlier, we’ll ignore the accuracy metric to evaluate the performance of the classifier on this imbalanced dataset. Here, we are more interested to know that which are the customers who’ll churn out in the coming months. Thereby, we’ll focus on metrics like precision, recall, F1-score to understand the performance of the classifiers for correctly determining which customers will churn.
Note: The SMOTE and its related techniques are only applied to the training dataset so that we fit our algorithm properly on the data. The test data remains unchanged so that it correctly represents the original data.

From the above, it can be seen on the actual imbalanced dataset, all 3 classifier models were not able to generalize well on the minority class compared to the majority class. As a result, most of the negative class samples were correctly classified. Due to this, there was less FP compared to more FN. After oversampling, a clear surge in Recall is seen on the test data. To understand this better, a comparative barplot is shown below for all 3 models:
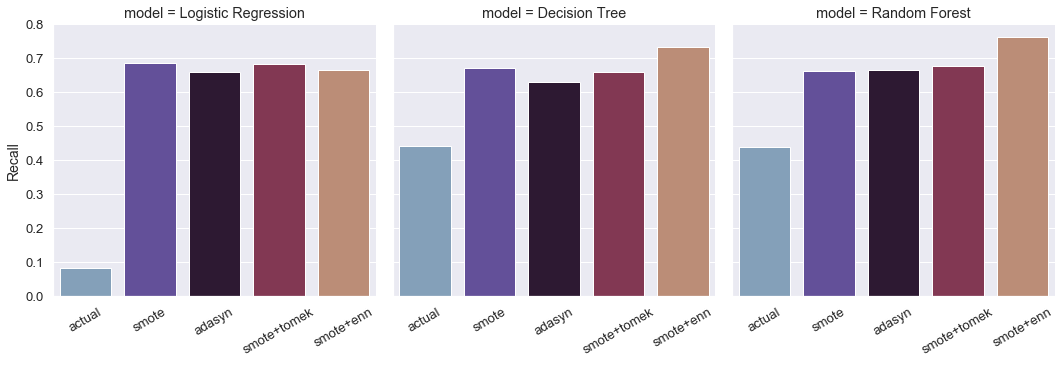
There is a decrease in precision, but by achieving a much recall which satisfies the objective of any binary classification problem. Also, the AUC-ROC and F1-score for each model remain more or less the same.
End Notes
The issue of class imbalance is just not limited to binary classification problems, multi-class classification problems equally suffer with it. Therefore, it is important to apply resampling techniques to such data so as the models perform to their best and give most of the accurate predictions.
You can check the entire implementation in my GitHub repository and try to apply them at your end. Do explore other techniques that help in handling an imbalanced dataset.
Frequently Asked Questions
A. SMOTE is an oversampling technique that generates synthetic samples from the minority class. It obtains a synthetically class-balanced or nearly class-balanced training set, then trains the classifier.
A. Smote is used for synthetic minority oversampling in machine learning. It generates synthetic samples to balance imbalanced datasets, specifically targeting the minority class.
A. Smote should be used when dealing with imbalanced datasets to improve the performance of machine learning models on minority class predictions.
A. The main difference between SMOTE and oversampling techniques is that SMOTE generates synthetic samples using interpolation between existing minority samples, while oversampling replicates existing minority samples to balance the dataset.
SMOTE may improve accuracy but can also create unrealistic synthetic samples, affecting accuracy. The impact depends on the dataset and model.
Consider alternative techniques like undersampling, cost-sensitive learning, or ensemble methods.
Experiment with different techniques to determine the best approach for your dataset.
References:
Learning from Imbalanced Data Sets by Alberto Fernández, Salvador García, Mikel Galar, Ronaldo C. Prati, Bartosz Krawczyk, Francisco Herrera









One of the best articles published in the recent times
very well written. It helped me a lot in my project. Thank you :)