
In my last blog, I introduced the concept of the Data Lake as a Consolidator and the critical success factor of applying robust Information Governance to this environment. In this post, I want to introduce an analogy to help visualize this environment and the parties involved.
So, a Data Lake as Consolidator. What does that really mean? Well, for me it means obtaining information from multiple sources and making it available to multiple targets – with a key differentiator of ensuring the targets do not need to know which source provided what information.
In other words, de-coupling sources from targets so that the focus is on the actual information is a key characteristic of a powerful, and useful, Data Lake.
This de-coupling provides a level of flexibility in that the addition, removal – and even the alteration of the access mechanism – of an involved system becomes much simpler and more efficient because you need focus only upon a single system, and not worry about how that system may, or may not, interact with others.
Stated another way, the Data Lake Consolidator can be described using the following purpose and value statements:
Purpose of the Data Lake:

The focus of the Data Lake is to provide a singular and common mechanism for the sharing of information across a wide variety of systems and solutions
Rationale/Value:
The benefit of the Data Lake is in the de-coupling of systems and removing point-to-point integration solutions to improve efficiencies and lower maintenance costs, while allowing both the removal and introduction of solutions without impacting any other solution or incurring the cost of integrating or de-integrating solutions
I like to use the analogy of an Aggregator – in that, the central repository (the Data Lake) pulls information from a variety of sources (suppliers), aggregates it (separates, combines, consolidates, repackages – or just leaves it as is) and presents this source independent view of the information to the targets (consumers). The following picture provides a diagrammatic representation of this analogy:
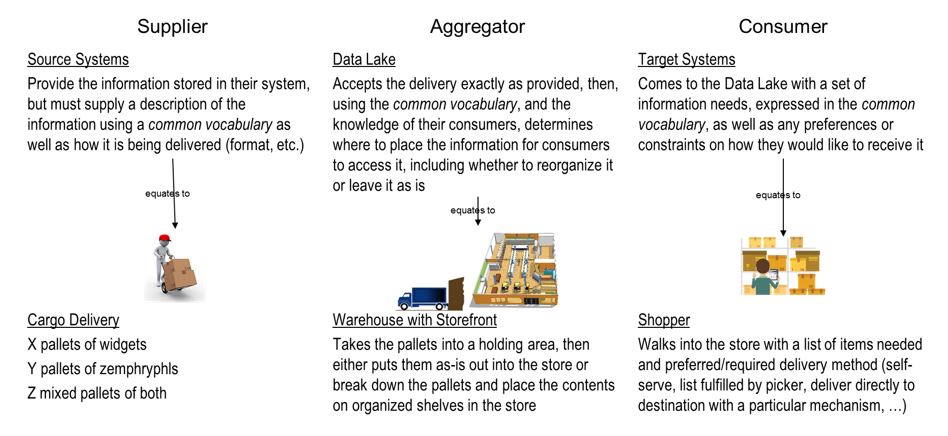
This real-world concept is applied in our day-to-day living all the time – and is the underlying model to all retail interactions. But, as indicated, the “warehouse” model is probably closest to the Data Lake concept because it also provides the “direct” access to the products of the supplier “as-delivered” (just sitting on a pallet) – which is one of the options in a Data Lake.
For the right consumer, sometimes it just makes sense to provide direct access, offering that option in concert with the “re-packaged” versions.
This model relies upon a couple key concepts: one being the reference to a “common vocabulary”, which I’ll discuss in a later post, and the other the roles of Supplier, Aggregator and Consumer.
It is critical to well-define and articulate these roles and their responsibilities so that all parties are “on the same page” as far as knowing how they play a part, and equally important, where the lines of demarcation lie between these roles. I will delve a little more deeply into these roles and responsibilities in my next post.