A Comprehensive Guide on Inferrd : The easiest way to deploy ML models
This article was published as a part of the Data Science Blogathon

Introduction
Deployment is a way to integrate your machine learning model into your existing production environment and make practical business decisions based on your data. This is one of the final stages of the machine learning life cycle and can be one of the most annoying. In this blog, we are going to cover the following topics.
• What is model deployment?
• Why model deployment is important?
• Introduction to inferrd
• Model deployment using inferrd in different environments
• Scikit-Learn
• Spacy
• Keras
• Tensorflow
• Pytorch
• Inference using inferrd
• Inferrd integration with Huggingface
What is model deployment?
As we mentioned in the introduction part, The process of using a trained ML model and making its predictions available to users and other systems is called deployment. Deployment is quite different from normal machine learning tasks such as data collection, feature engineering, feature selection, model building, and model evaluation.
Why model deployment is important?
Before moving to the further sections of this document, you have to be aware of the most important question and its answer.
“What is the importance of model deployment in data science?“
To use the model for real-world decision-making, you need to use it effectively in production. If you do not have reliable and practical knowledge from the model, the effectiveness of the model will be severely limited. Deploying a model is one of the most difficult processes of the machine learning life cycle. Coordination between data scientists, DevOps and business people is needed to ensure that the model works in the production environment of the company. To get the most out of your machine learning model, it’s important to seamlessly implement it in production so your enterprise can start making practical decisions.
If you get the answer to the first question then definitely the next question waiting for you😇.
“How to deploy the model?“
Introduction to inferrd
Inferrd makes it easy to deploy machine learning models to the GPU without having to deal with the underlying infrastructure. This allows you to convert your model to a product more quickly. It is built for browsers and does not require a download. All you need is an account to start the deployment. In the background, it works with your model on a super-powerful GPU server that scales your model to millions of requests as needed.
Once you created an account and deploy a model using inferrd, it provides you a dashboard where you can see all your model status including model version, model latency in milliseconds, total requests..etc. A sample inferrd dashboard is given below.
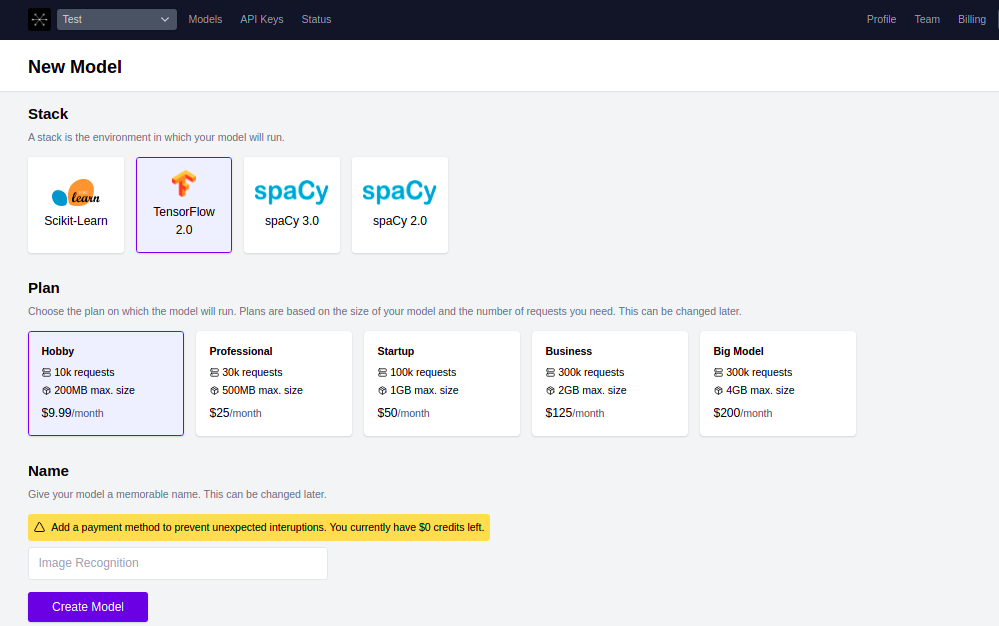
Please check the official documentation of inferrd for more details.
Model deployment using inferrd in different environments
For the second method, inferrd python package should be installed using pip.
!pip install inferrd
Once the inferrd package is installed, you need to get your MODEL_API_KEY key from the profile page on inferrd.com and you will receive an email once it is deployed.
Scikit-Learn
Inferrd natively supports ScikitLearn. It’s a great library to try out a simple regression or classifier without using deep learning.
import inferrd
inferrd.auth('MODEL_API_KEY')
model = # ... define your Scikit model here
inferrd.deploy_scikit(model, 'Your scikit model name')
This will start deploying your scikit-learn model on Inferrd.
Spacy
Inferrd natively supports SpaCy with GPU acceleration. Try the following code to deploy the Spacy model.
import inferrd
inferrd.auth('MODEL_API_KEY')
nlp = # ... define your Spacy model here
inferrd.deploy_spacy(nlp, 'Your Spacy model name')
This will start deploying your spacy model on Inferrd.
Keras
Keras is natively supported by Inferrd and optional GPU acceleration is offered. All you need to deploy to it is the exported version of your Keras model. With Keras, the export of a model can be done in a single line.
import keras
model = # ... define your Keras model here
model.save('model_to_export')
This code will generate a folder called model_to_export. Upload that folder to Inferrd to deploy your model.
Tensorflow
Inferrd natively supports Tensorflow with GPU acceleration. Try the following code to deploy the Tensorflow model.
import inferrd
inferrd.auth('MODEL_API_KEY')
tf_model = # ... define your tensorflow model here
inferrd.deploy_tf(tf_model, 'Your Tensorflow model name')
This will start deploying your Tensorflow model on Inferrd.
Pytorch
Pytorch is natively supported by Inferrd. All you need to deploy to it is the exported version of your Pytorch model. With Pytorch, the export of a model can be done in a single line.
import torch model = # ... define your Pytorch model here torch.save(model, 'model_to_export')
This code will generate a folder called model_to_export. Upload that folder to Inferrd to deploy your model.
Inference using inferrd
Our goal is to make it easy to build AI-powered applications. That’s why we create packages for the most common use cases that are easy to use and install.
To make a prediction you will need to find your Model Id. It’s at the top of your model’s README page:
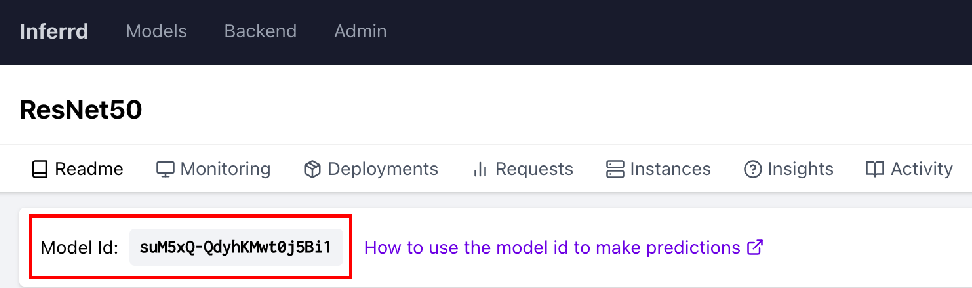
There are multiple ways for inference using inferrd such as using Node.js, React, Python, etc.
To use a hosted model in your Python app, install the inferrd package as mentioned above
After the installation, we can simply access the deployed model using the Model Id and infer from the model. The package has one method called call_model to make an inference.
import inferrd
model = inferrd.get('Model Id')
inputs = #...put your inputs here
prediction = model(inputs)
End Notes
Hope this overview has helped you to understand the basic concepts and steps of machine learning model deployment using inferrd. Obviously, there are lots of other methods and tools in data science for the machine learning deployment among that the importance of inferrd is its ease of use and simplicity.
So why wait…Deploy your model using it. If you face any difficulty while deploying the model or have any ideas/suggestions/comments, feel free to post them in the comments section below.
Happy coding..😊







