Bamboolib — Learn and use Pandas without Coding
Have you ever been frustrated by doing data exploration and manipulation with Pandas?
With so many ways to do the same thing, I get spoiled by choice and end up doing absolutely nothing.
And then for a beginner, the problem is just the opposite as in how to do even a simple thing is not appropriately documented. Understanding Pandas syntax can be a hard thing for the uninitiated.
So what should one do?
The creators of Bamboolib had an idea that solved this problem — Why not add a GUI to pandas?
The idea is to “Learn and use pandas without coding.” Now the idea may have started simple, but I found Bamboolib to be so much more when it comes to data exploration and data cleaning.
This post is about setting up and using Bamboolib for your data.
Installing Bamboolib
Installation is pretty simple with:
pip install bamboolib
To get bamboolib to work with Jupyter and Jupyterlab, I will need to install some additional extensions. Since I like working with Jupyter Notebook, I installed the Jupyter Notebook extensions via the following command:
jupyter nbextension enable --py qgrid --sys-prefix
jupyter nbextension enable --py widgetsnbextension --sys-prefix
jupyter nbextension install --py bamboolib --sys-prefix
jupyter nbextension enable --py bamboolib --sys-prefix
If you want the process to install for Jupyterlab, here is the process .
Verifying Bamboolib Installation
To check if everything works as intended, you can open up a Jupyter notebook, and execute the following commands:
import bamboolib as bam
import pandas as pd
data = pd.read_csv(bam.titanic_csv)
bam.show(data)
The first time you run this command, you will be asked to provide a Licence key. The key is needed if you want to use bamboolib over your own data. Since I wanted to use bamboolib for my own project, I got the key from one of Bamboolib founder Tobias Krabel who was gracious enough to provide it to me to review. You can, however, buy your own from https://bamboolib.8080labs.com/pricing/ . If you want to see the library in action before purchasing the key, you can try out the live demo .

Once bamboolib is activated, the fun part starts. You can see the output of Bamboolib like this. You can choose to play with the options it provides.

So let’s try Bamboolib with our exciting data source, we all have seen Titanic data aplenty.
To do this, I will be using the Mobile Price Classification data from Kaggle. In this problem, we have to create a classifier that predicts the price range of mobile phones based on the features of a mobile phone. So lets start this up with Bamboolib.
train = pd.read_csv("../Downloads/mobile-price-classification/train.csv")
bam.show(train)
We need to do a simple call to bam.show(train) to start Bamboolib.
Easy Data Exploration
Bamboolib helps a great bit for Exploratory Data analysis. Now, Data exploration is an integral part of any data science pipeline. And writing the whole code for data exploration and creating all the charts is complicated and needs a lot of patience and effort to get right. I will admit sometimes I do slack off and am not able to give enough time for it.
Bamboolib makes the whole Data Exploration exercise a breeze.
For example. Here is a glimpse of your data, once you click on Visualize Dataframe.

You get to see the missing values in each column, as well as the number of unique values and a few instances.
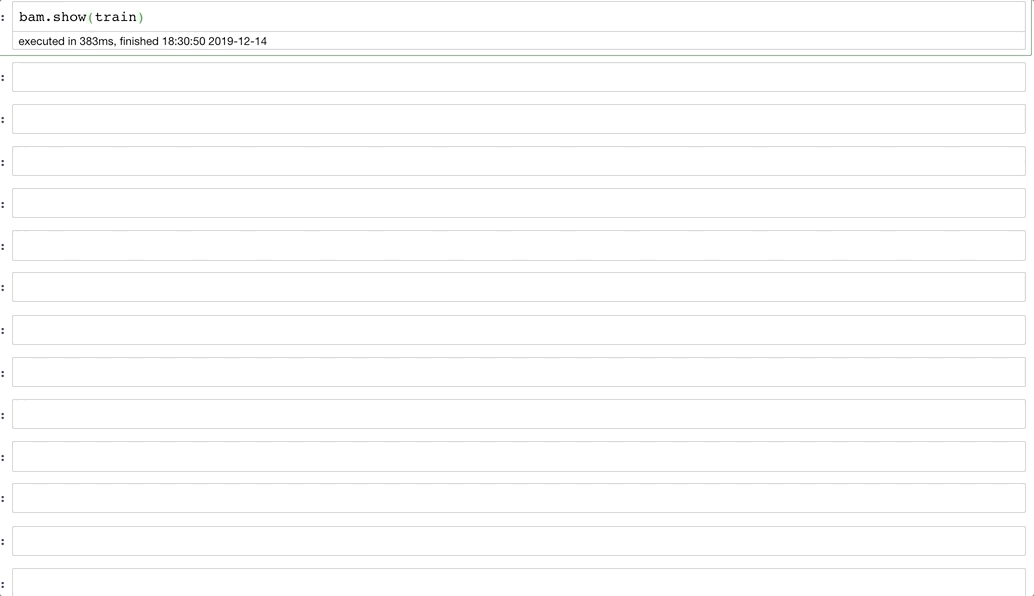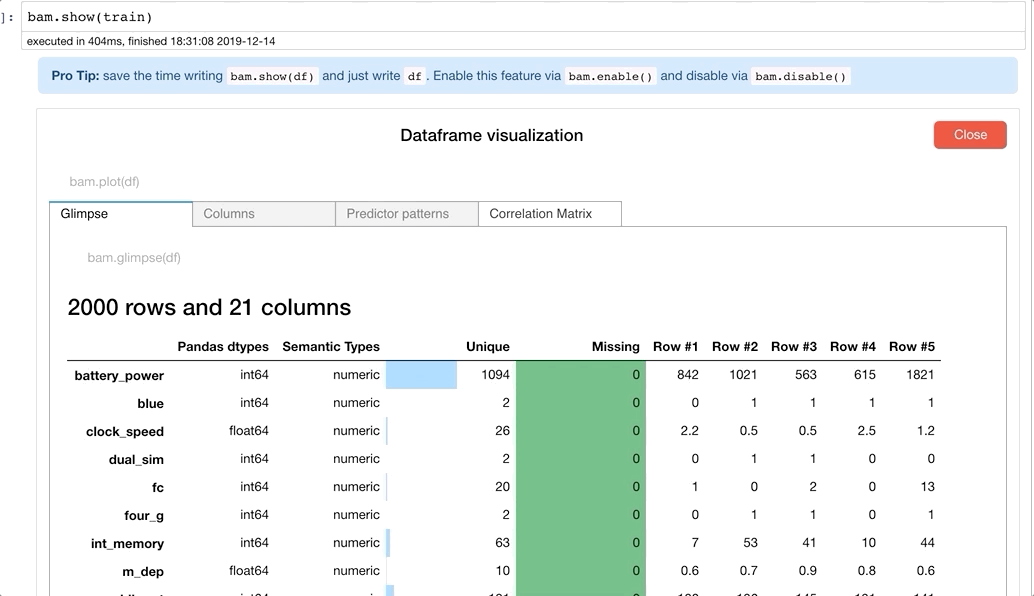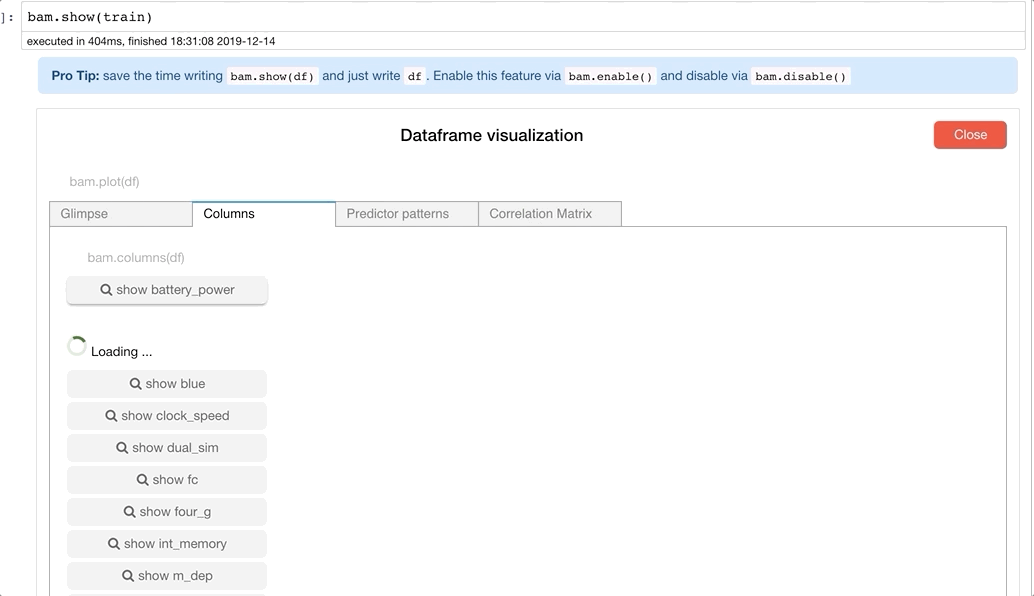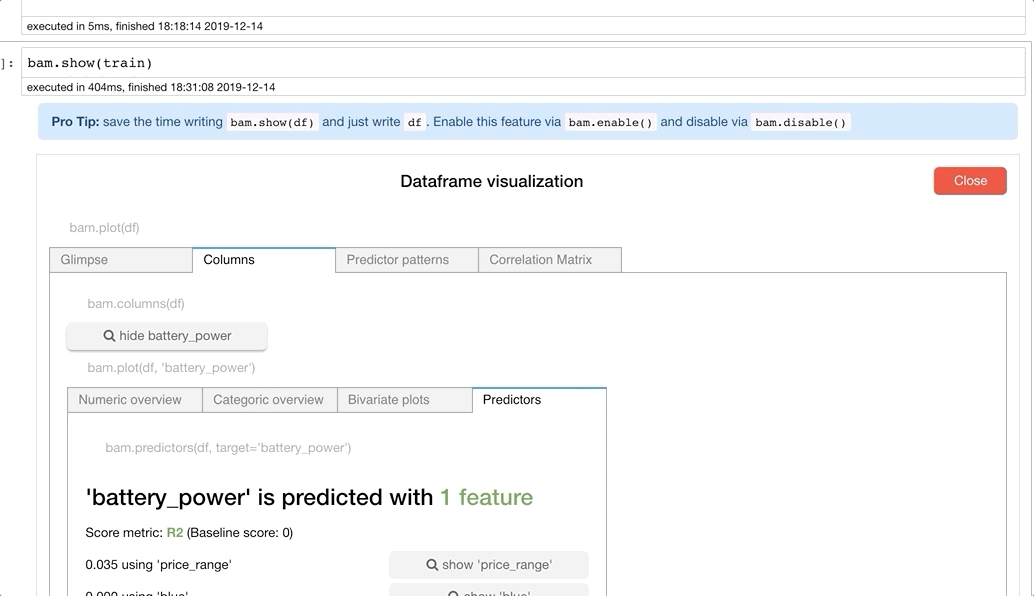
But that’s not all. We can get univariate column-level statistics and information, as well. So lets get some information about our target variable — Price Range.

Here we deep-dive into the target column and can see univariate column statistics as well as the most important predictors for our target column. It looks like RAM and battery power are the most important predictors for the price range. Nice.
Let’s take a look at how RAM influences the price range. We can use bivariate plots for this.

Getting such beautiful plots with standard Python libraries like seaborn or plotly usually takes some amount of code. Although plotly_express helps a lot in this by giving simple functions for most charts, Bamboolib creates a lot of important charts for us automatically.
Above, we can see that as RAM increases, the price range increases. We also see a weighted F1 Score of 0.676 for the RAM Variable. You can do this for every variable in your dataset and try to get a sense of your data.
One can also export the code of these charts to use in some presentation/ export these charts as PNG.
To do this just copy the code fragment that shows above each graph. For example, you can copy and run the code to see price_range vs ram, and you will see an option to download these graphs as PNG. In the backend, they are all plotly graphs.
bam.plot(train, 'price_range', 'ram')

GUI Based Data Munging
Have you ever faced the problem of forgetting pandas code to do something and going to stack overflow and getting lost in various threads? If yes, here is a Minimal Pandas refresher. Or you can use Bamboolib as per your preference.
Bamboolib makes it so easy to do things and not get lost in the code. You can drop columns, filter, sort, join, groupby, pivot, melt (Mostly everything you would like to do with a dataset) all by using the simple GUI provided.
For example, here I am dropping the missing values from the target column, if any. You can add multiple conditions, as well.

The best part is that it also gives us the code. Here the code to drop the missing values gets populated in the cell automatically.
train = train.loc[train['price_range'].notna()]
train.index = pd.RangeIndex(len(train))
It works just like Microsoft Excel for business users while providing all the code to slice and dice the data for the advanced ones. You can try to play with the other options to get familiar.
Here is another example of how to use groupby. It is actually pretty intuitive.

The code for this gets populated as:
train = train.groupby(['price_range']).agg({'battery_power': ['mean'], 'clock_speed': ['std']})
train.columns = ['_'.join(multi_index) for multi_index in train.columns.ravel()]
train = train.reset_index()
You can see how it takes care of multi_index as well as ravel for us, which are a bit difficult to understand and deal with.
Conclusion
The GUI of Bamboolib is pretty intuitive, and I found it an absolute joy to work with. The project is still in its beginnings, but what a beginning it has been.
I can surely say that this library is pretty useful for beginners who want to learn to code in Pandas as it provides them access to all the necessary functions without being bothersome.
While I will still focus on understanding the basics of Pandas and would advise looking at the output of Bamboolib to learn Pandas as well, I would like to see how the adoption of Bamboolib happens in the future.
Let me know your thoughts as well in the comments.
If you want to learn more about Pandas, I would like to call out an excellent course on Introduction to Data Science in Python from the University of Michigan or check out my previous post on how to work with Pandas .
I am going to be writing more of such posts in the future too. Let me know what you think about them. Follow me up at <strong>Medium</strong> or Subscribe to my <strong>blog</strong>
About Me

I’m a Machine Learning Engineer based in London, where I am currently working with Roku .
Know More