Most powerful Python Functions apply() and lambda()
Overview
pandas is a most powerful, easy, and flexible to use open-source data analysis tool, built on top of the Python programming language.
I’ve been using Pandas for a long time, and it never ceases to amaze me with new features, shortcuts, and many methods to accomplish a task.
However, I’ve discovered that adhering to some of the conventions I’ve learned has been beneficial over time.
Some of the most useful pandas features I’ve discovered are ‘apply()’ and ‘lambda()’.
When I’m stuck creating complex logic for a new column or filter, I turn to apply and lambda.
When a company comes to you with a special request, this happens frequently.
The goal of this post is to show you how powerful apply and lambda are.
Will be using a data set of 1,000 popular movies on IMDB in the last 10 years. You can also follow along in the Kaggle.
import numpy as np # linear algebra import pandas as pd # pandas defaults pd.options.display.max_columns = 500 pd.options.display.max_rows = 500 import os
Reading the Data
#renaming some cols
df.rename(columns = {'Revenue (Millions)':'Rev_M','Runtime (Minutes)':'Runtime_min'},inplace=True)
Creating a Column
There are several ways to make a new column. You can pretty much use simple fundamental arithmetic if you want a column that is a sum or difference of columns. Using IMDB and Normalized Metascore, I calculate the average rating.
df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2
Let’s say I want to increase the IMDB rating by one of the films is a thriller, but only if the IMDB rating is less than or equal to 10. Also, if the film is a comedy, I want to deduct one point from the ranking.
How do we go about doing that? I use to apply/lambda whenever I come across such difficult scenarios. Let me first demonstrate how I want to accomplish this.
def custom_rating(genre,rating):
if 'Thriller' in genre:
return min(10,rating+1)
elif 'Comedy' in genre:
return max(0,rating-1)
else:
return rating
df['CustomRating'] = df.apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
- You create a function that takes the column values you want to experiment with and creates your reasoning. The genre and rating columns are the only ones we use in this case.
- You can use apply the function with lambda with axis=1. The general syntax is:
Because you just need to care about the custom function, you should be able to design pretty much any logic with apply/lambda.
Filtering a dataframe
Filtering and subsetting data frames are simple with Pandas. Normal operators and &,|, operators can be used to filter and subset data frames.
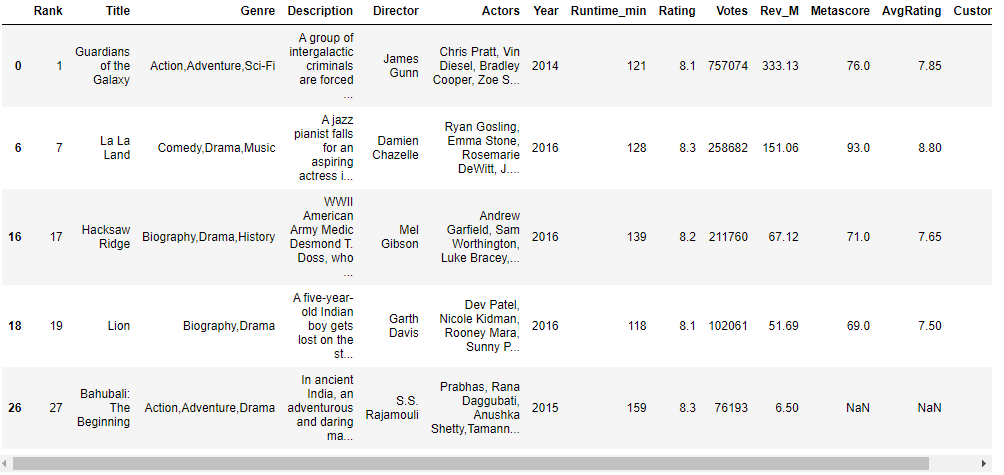
# Single condition: dataframe with all movies rated greater than 8 df_gt_8 = df[df['Rating']>8] df_gt_8.head()
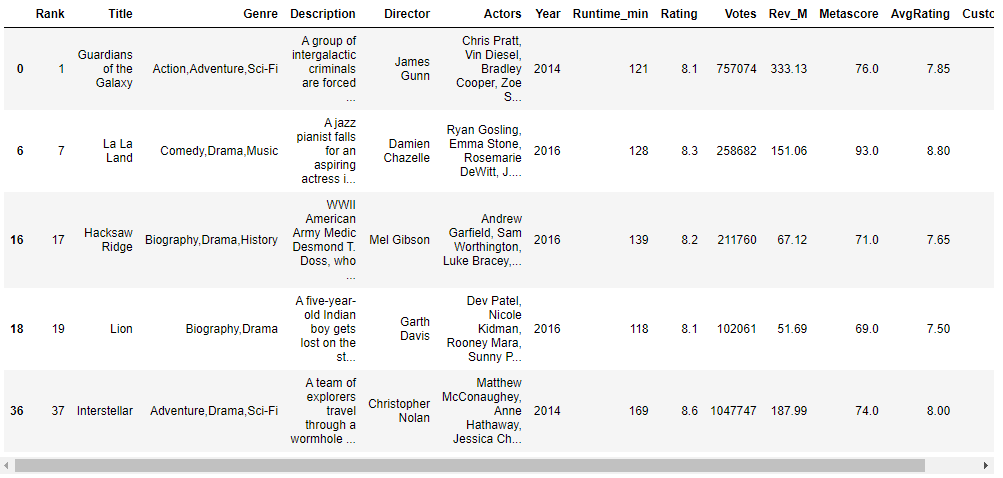
# Multiple conditions: AND - dataframe with all movies rated greater than 8 and having more than 100000 votes And_df = df[(df['Rating']>8) & (df['Votes']>100000)] And_df.head()
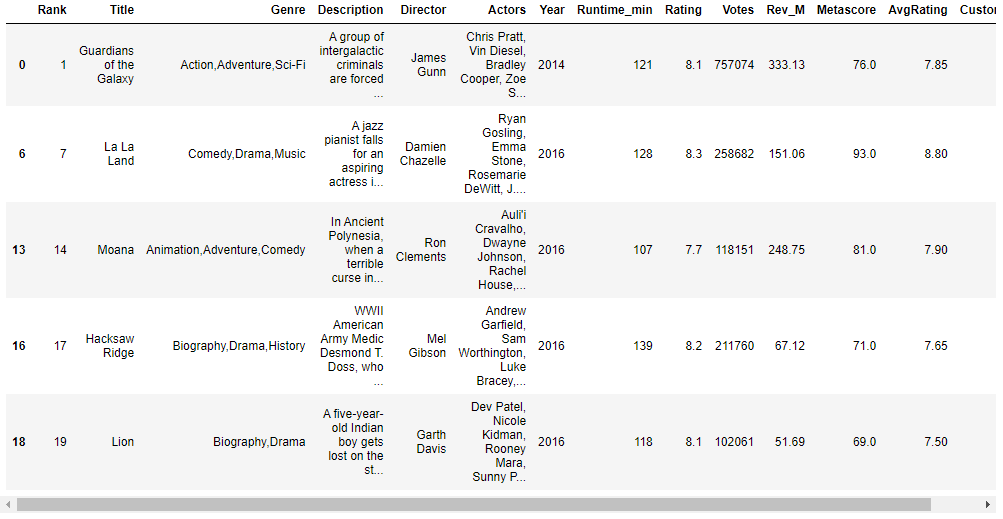
# Multiple conditions: OR - dataframe with all movies rated greater than 8 or having a metascore more than 90 Or_df = df[(df['Rating']>8) | (df['Metascore']>80)] Or_df.head()
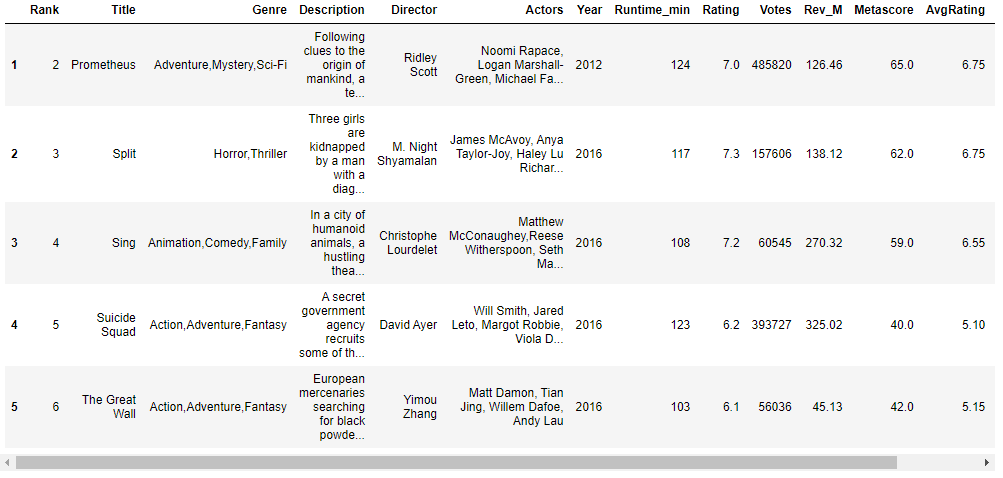
# Multiple conditions: NOT - dataframe with all emovies rated greater than 8 or having a metascore more than 90 have to be excluded Not_df = df[~((df['Rating']>8) | (df['Metascore']>80))] Not_df.head()
It’s all pretty easy.
However, complicated filtering techniques may be required at times.
And there are situations when we need to do operations that the above format will not allow us to execute.
Let’s say we want to find rows where the number of words in the movie title is higher than or equal to four. What would you do if you were in control of the operation?
You’ll get an error if you try the below. Nothing as easy as splitting with a series appears to be possible.
# Single condition: dataframe with all movies rated greater than 8 df_gt_8 = df[df['Rating']>8] # Multiple conditions: AND - dataframe with all movies rated greater than 8 and having more than 100000 votes And_df = df[(df['Rating']>8) & (df['Votes']>100000)] # Multiple conditions: OR - dataframe with all movies rated greater than 8 or having a metascore more than 90 Or_df = df[(df['Rating']>8) | (df['Metascore']>80)] # Multiple conditions: NOT - dataframe with all emovies rated greater than 8 or having a metascore more than 90 have to be excluded Not_df = df[~((df['Rating']>8) | (df['Metascore']>80))]
new_df = df[len(df['Title'].split(" "))>=4]
One method is used to apply and create a column that contains the number of words in the title and then filter on that column.
#create a new column
df['num_words_title'] = df.apply(lambda x : len(x['Title'].split(" ")),axis=1)
#simple filter on new column
new_df = df[df['num_words_title']>=4]
new_df.head()
And as long as you don’t need to build a lot of columns, this is a perfectly appropriate situation. However, I prefer the following:
new_df = df[df.apply(lambda x : len(x['Title'].split(" "))>=4,axis=1)]
new_df.head()
Now that you know that all you have to do to filter is create a column of booleans, you can use any function/logic in your ‘apply()’ statement to create whatever sophisticated logic you want.
Let’s have a look at another example. I’ll try to do something a little more complicated merely to demonstrate the framework.
We wish to locate movies whose box office receipts are smaller than the year’s average box office receipts.
year_revenue_dict = df.groupby(['Year']).agg({'Rev_M':np.mean}).to_dict()['Rev_M']
def bool_provider(revenue, year):
return revenue<year_revenue_dict[year]
new_df = df[df.apply(lambda x : bool_provider(x['Rev_M'],x['Year']),axis=1)]
new_df.head()
Here is a function that may be used to write any logic. As long as we can deal with simple variables, this gives us a lot of ability for complicated filtering.
Change Column Types
I also use apply to change column types because I don’t want to remember the syntax and because it allows me to perform a lot more complex things. In Pandas, the standard syntax for changing column type is as type. So, assuming I had a price column in my data in str format. This is something I could do:
df['Price'] = newDf['Price'].astype('int')
However, it is not always successful. It’s possible that you’ll receive the following message: ValueError: ‘13,000’ is an incorrect long() literal with base 10. That is, a string with “,” cannot be cast to an int. To do so, we’ll need to remove the comma first. After repeatedly encountering this issue, I’ve decided to leave as type and instead rely on ‘apply()’ to switch column types.
df['Price'] = df.apply(lambda x: int(x['Price'].replace(',', '')),axis=1)
And lastly, there is progress_apply
The (tqdm) package includes a single function called progress apply.
And it’s helped me save a lot of time.
When you have a lot of rows in your data or you end up writing a rather complex apply function, you may notice that apply takes a long time.
When working with Spacy, I’ve seen applications take hours. In such circumstances, the progress bar with apply can be useful.
You can do this with (tqdm).
Simply replace apply with progress apply after the initial imports at the top of your notebook, and everything will stay the same.
from tqdm import tqdm, tqdm_notebook tqdm_notebook().pandas() new_df['rating_custom'] = df.progress_apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
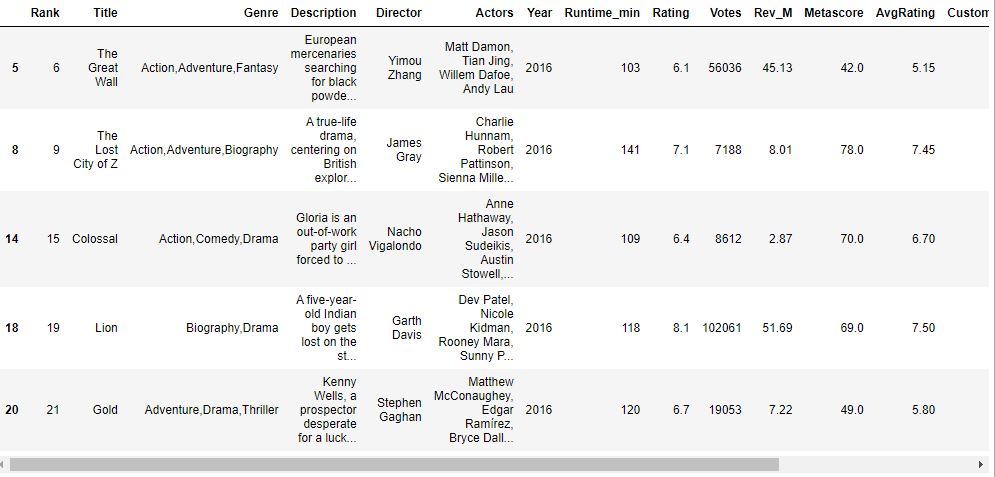
new_df.head()
Conclusion
The apply and lambda functions allow you to handle a variety of difficult tasks while modifying data.
I don’t think I need to be worried about anything when using Pandas because I can use them effectively.
I tried to describe how it works in this post. There may be more ways of achieving what I’ve just described.
However, I prefer to apply/lambda to map/apply map because it is more readable and more suited to my workflow.
EndNote
Thank you for reading!
I hope you enjoyed the article and increased your knowledge.
Please feel free to contact me on Email
Something not mentioned or want to share your thoughts? Feel free to comment below And I’ll get back to you.
About the Author
Hardikkumar M. Dhaduk
Data Analyst | Digital Data Analysis Specialist | Data Science Learner
Connect with me on Linkedin
Connect with me on Github







