DeepMind Has Quietly Open Sourced Three New Impressive Reinforcement Learning Frameworks
Three new releases that will help researchers streamline the implementation of reinforcement learning programs.

Deep reinforcement learning(DRL) has been at the center of some of the biggest breakthroughs of artificial intelligence(AI) in the last few years. However, despite all its progress, DRL methods remain incredibly difficult to apply in mainstream solutions given the lack of tooling and libraries. Consequently, DRL remains mostly a research activity that hasn’t seen a lot of adoption into real world machine learning solutions. Addressing that problem requires better tools and frameworks. Among the current generation of artificial intelligence(AI) leaders, DeepMind stands alone as the company that has done the most to advance DRL research and development. Recently, the Alphabet subsidiary has been releasing a series of new open source technologies that can help to streamline the adoption of DRL methods.
As a new deep learning technique, the adoption of DRL faces challenges beyond the simple implementation of algorithms. Training datasets, environments, monitoring-optimization tools as well as well-designed experiments are needed to streamlined the adoption of DRL techniques. This is particularly true in the case of DRL given that its mechanics differ from most traditional machine learning methods. DRL agents attempt to master a task by trial and error in a given environment. In that setting, the robustness of the environments and experiments play a primordial role in the knowledge developed by a DRL agent.
DRL has been the cornerstone of DeepMind efforts to advance AI. Starting with the famous AlphaGo and continuing with major milestones in areas such as healthcare, ecological research and, of course, gaming, DeepMind has applied DRL methods to major AI challenges. To achieve those milestones, DeepMind has had to build many proprietary tools and frameworks that streamline the training, experimentation and management of DRL agents at scale. Very quietly, DeepMind has been open sourcing several of those technologies so that other researchers can use them to advance the current state of DRL methods. Recently : DeepMind open sourced three different DRL stacks that merit a deeper exploration.
OpenSpiel

Games play a prominent role in the training of DRL agents. Like no other dataset, games are intrinsically based on trial and reward mechanics which can be used to train a DRL agent. However, as you can imagine, gaming environments are far from trivial to assemble.
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. The purpose of OpenSpiel is to promote general multiagent reinforcement learning across many different game types, in a similar way as general game-playing but with a heavy emphasis on learning and not in competition form. The current version of OpenSpiel contains implementations of over 20 different games of various sorts (perfect information, simultaneous move, imperfect information, grid-world games, an auction game, and several normal-form / matrix games.
The core OpenSpiel implementation is based on C++ with Python bindings which facilitate its adoption in different deep learning frameworks. The framework incorporates a portfolio of games that allow DRL agents to master cooperative and competitive behaviors. Similarly, OpenSpiel includes a diverse portfolio of DRL algorithms including search, optimization and single-agent.
SpriteWorld

A few months ago, DeepMind published a very impressive research paper introducing a Curious Object-Based seaRch Agent (COBRA) that used reinforcement learning to recognize objects in a given environment. The COBRA agent was trained using a series of two-dimensional games in which figures could move freely. The environment used to train the COBRA was known as SpriteWorld and is another one of the recent DeepMind open source contributions.
Spriteworld is a python-based RL environment that consists of a 2-dimensional arena with simple shapes that can be moved freely. More specifically, SpriteWorld is a 2-dimensional square arena with a variable number of colored sprites, freely placed and rendered with occlusion but no collisions. The SpriteWorld environment is based on a series of key characteristics:
- The multi-object arena reflects the compositionality of the real world, with cluttered scenes of objects that can share features yet move independently. This also provides ways to test robustness to task-irrelevant features/objects and combinatorial generalization.
- The structure of the continuous click-and-push action space reflects the structure of space and motion in the world. It also allows the agent to move any visible object in any direction.
- The notion of an object is not provided in any privileged way (e.g. no object-specific components of the action space) and can be fully discovered by agents.
SpriteWorld trains each DRL agent on three main tasks:
- Goal-Finding. The agent must bring a set of target objects (identifiable by some feature, e.g. “green”) to a hidden location on the screen, ignoring distractor objects (e.g. those that are not green)
- Sorting. The agent must bring each object to a goal location based on the object’s color.
- Clustering. The agent must arrange the objects in clusters according to their color.
bsuite
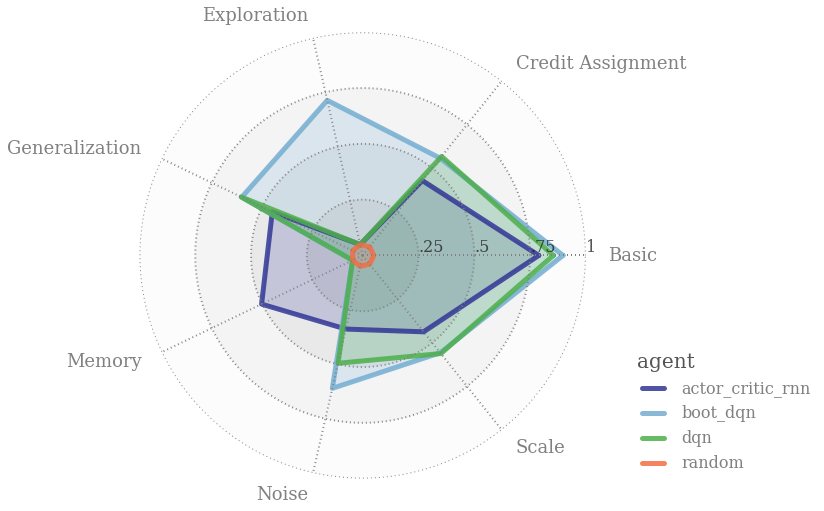
The Behaviour Suite for Reinforcement Learning (bsuite) attempt to be MNIST of reinforcement learning. Specifically, bsuite is a collection of experiments designed to highlight key aspects of agent scalability. These experiments embody fundamental issues, such as ‘exploration’ or ‘memory’ in a way that can be easily tested and iterated. Specifically, bsuite has two main objectives:
- To collect clear, informative and scalable problems that capture key issues in the design of efficient and general learning algorithms.
- To study agent behavior through their performance on these shared benchmarks.
The current implementation of bsuite automates the execution of these experiments across different environment and collects the corresponding metrics that can simplify the training of DRL agents.
As you can see, DeepMind has been very active in the development of new reinforcement learning technologies. OpenSpiel, SpriteWorld and bsuite can be incredible assets for research teams embarking in their reinforcement learning journey.
Original. Reposted with permission.
Related:
- Beyond Neurons: Five Cognitive Functions of the Human Brain that we are Trying to Recreate with Artificial Intelligence
- Introducing IceCAPS: Microsoft’s Framework for Advanced Conversation Modeling
- How DeepMind and Waymo are Using Evolutionary Competition to Train Self-Driving Vehicles