

This post was co-authored by two Cisco Employees as well: Karthik Krishna, Silesh Bijjahalli
Today’s enterprise data analytics teams are constantly looking to get the best out of their platforms. Storage plays one of the most important roles in the data platforms strategy, it provides the basis for all compute engines and applications to be built on top of it. Businesses are also looking to move to a scale-out storage model that provides dense storages along with reliability, scalability, and performance. Cloudera and Cisco have tested together with dense storage nodes to make this a reality.
Cloudera has partnered with Cisco in helping build the Cisco Validated design (CVD) for Apache Ozone. This CVD is built using Cloudera Data Platform Private Cloud Base 7.1.5 on Cisco UCS S3260 M5 Rack Server with Apache Ozone as the distributed file system for CDP.
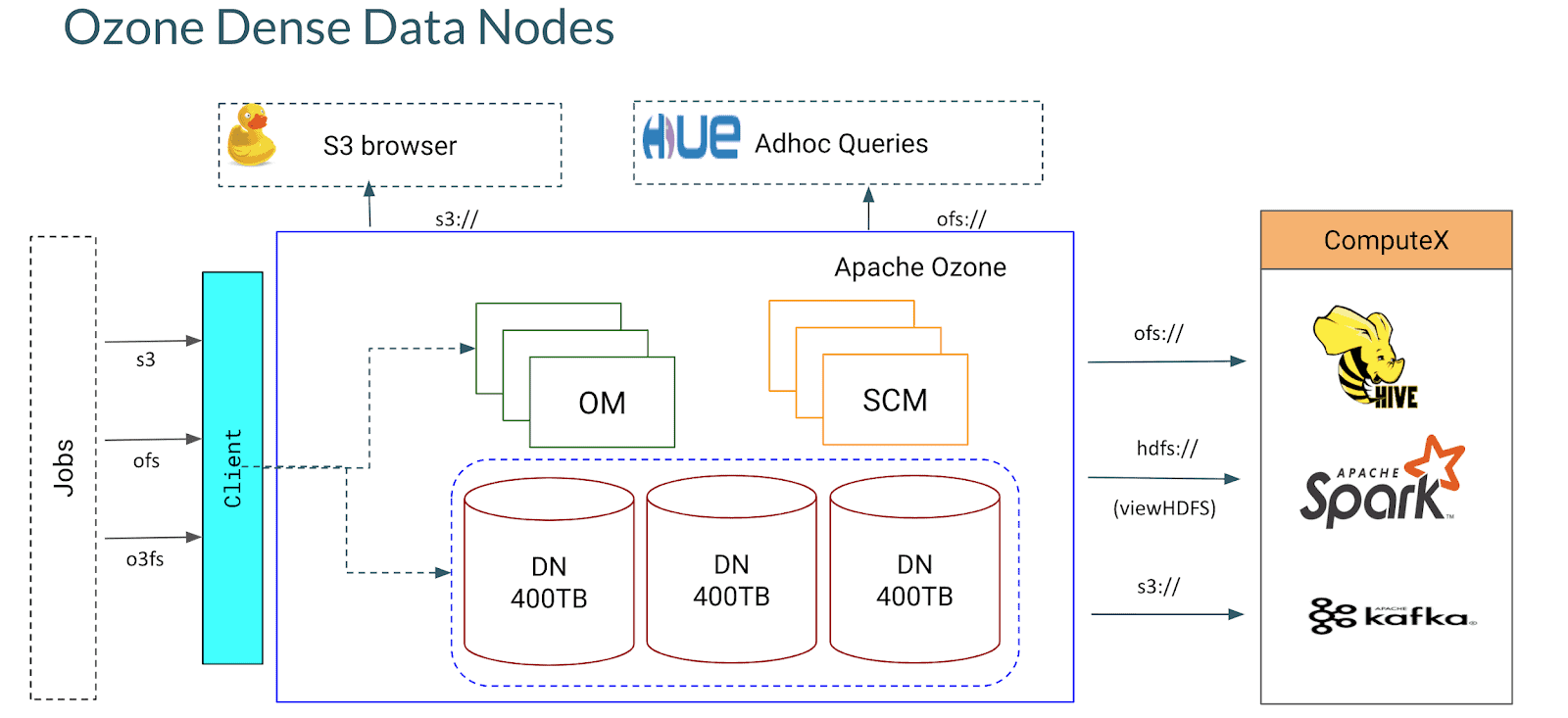
APACHE OZONE DENSE DEPLOYMENT CONFIGURATION
Apache Ozone is one of the major innovations introduced in CDP, which provides the next generation storage architecture for Big Data applications, where data blocks are organized in storage containers for larger scale and to handle small objects. This has been a major architectural enhancement on how Apache Ozone manages data at scale in a data lake.
Apache Ozone brings the best of both HDFS and Object Store:
- Overcomes HDFS limitations
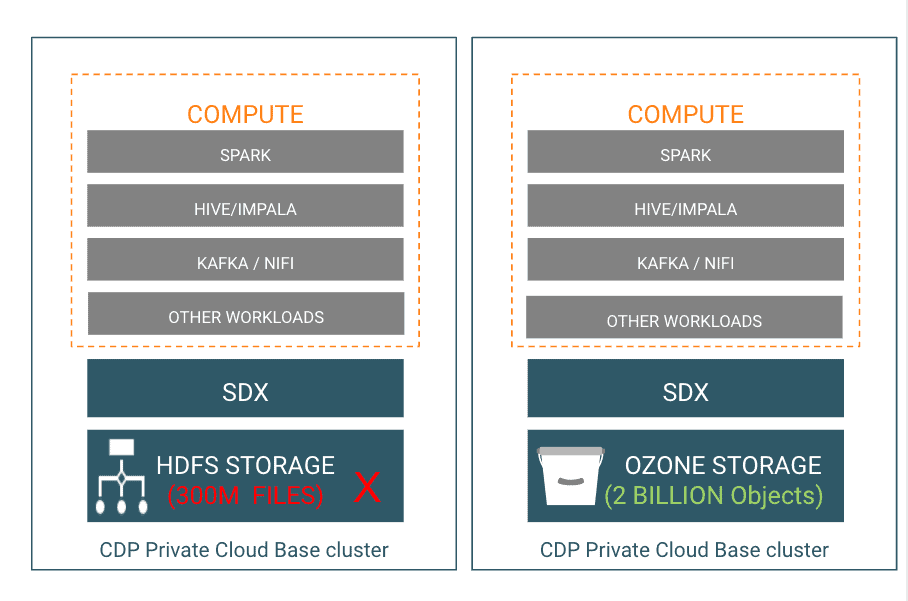
- Can support billions of files ( tested up to 10 billion files) in contrast with HDFS which runs into scalability thresholds at 400 million files
- Can currently support 400 TB/node with the potential to support 1 PB/node at a later point in time unlike HDFS which only supports up to 100 TB/node
- Supports 16TB drives unlike HDFS which only supports up to 8 TB drives
- Exabyte scale
- Overcome Object Store limitations
- Apache Ozone, unlike other object stores, can support large files with linear performance. Like HDFS, Apache Ozone breaks files into smaller chunks (other Object stores fail to do this and don’t perform linearly with large files as large files are served through a single node in most object stores slowing down performance), and these smaller chunks in Apache Ozone are read from all the different nodes, enabling linear performance without the size of the file creating any performance issues, thus, solving the large file problems often hit in object stores.
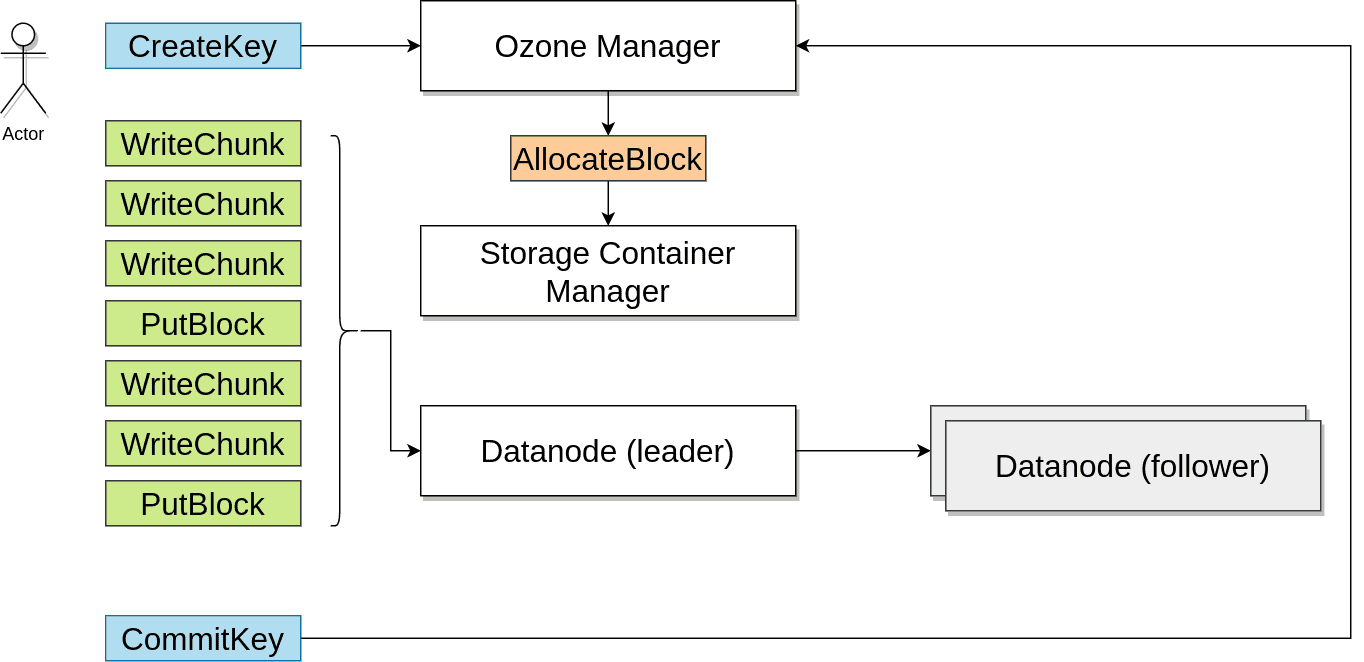
-
- Separates control and data plane enabling high performance. Supports very fast reads from multiple replicas
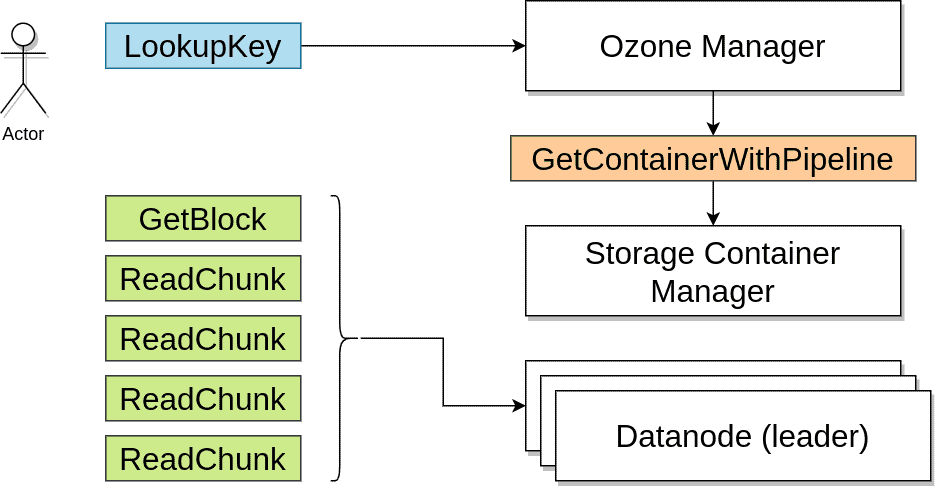
- Data from HDFS can be easily migrated to Apache Ozone with familiar tools like distcp. Apache Ozone handles both large and small size files.
- Ozone provides an easy to use monitoring and management console using recon
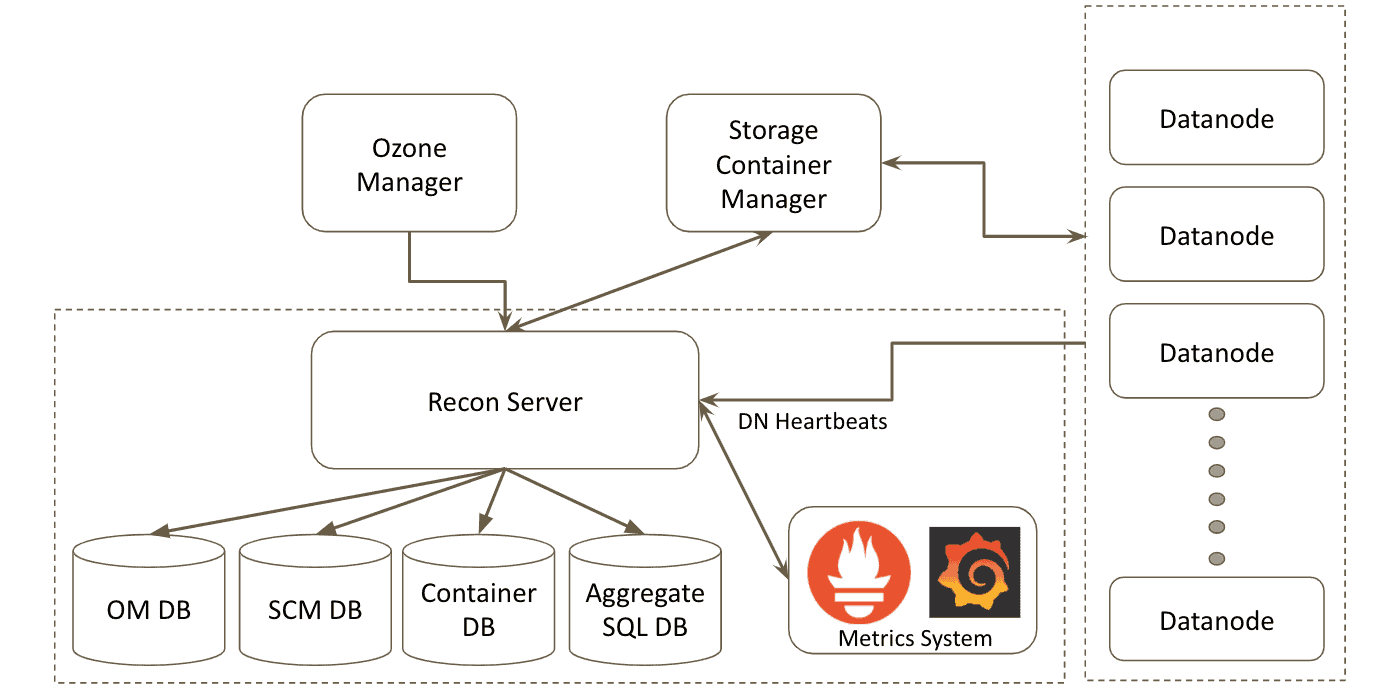
-
- Collects and aggregates metadata from components and present cluster state.
- Metadata in cluster is disjoint across components
- No one component can compute overall state of the cluster.
- As a user/support engineer of Ozone, I may want to:
- Look at details of volumes/buckets/keys/containers/pipelines/datanodes.
- Given a file, find out what nodes/pipeline is it part of.
- Find out whether the data distribution across Datanodes, and within disks in a Datanode is good.
- Find out if my file blocks are missing (or under-replicated)
- Supports Disaggregation of compute and storage
Testing Methodology
Data Generation at Scale
A data generator tool was written to create fake data for Ozone. It works by writing synthetic file system entries directly into Ozone’s OM, SCM, and DataNode RocksDB, and then writing fake data block files on DataNodes. This is significantly faster than writing real data using an application or another client. By running this tool in parallel on all storage nodes in the cluster we can fill up all the 400TB nodes in the cluster in less than a day.
With this tool, we were able to generate large amounts of data and certify Ozone on dense storage hardware. We made several enhancements in the product to improve, scale, and performance to handle the large density per node.
Standard Benchmarks
We benchmarked Impala TPC-DS performance on this test setup. The query templates and sample queries used are compliant with the standards set out by the TPC-DS benchmark specification and include only minor query modifications (MQMs) as set out by section 4.2.3 of the specification. All of these scripts can be found at, impala-tpcds-kit. Impala local caching was turned on while running this benchmark. The results of this testing indicate that the performance of 70% of the queries either matched or improved as compared to the same queries running with HDFS as the filesystem.
Failure Handling
Loss of one or more dense nodes triggers significant re-replication traffic. For data durability and availability, it is important that the file system should be quickly recovered from Hardware failures. Ozone includes optimizations to recover efficiently from the loss of dense nodes including the use of the multi-RAFT feature of Apache Ozone to get better distribution of data and avoid replication from being bottlenecked on fewer nodes.
Cloudera will publish separate blog posts with results of performance benchmarks.
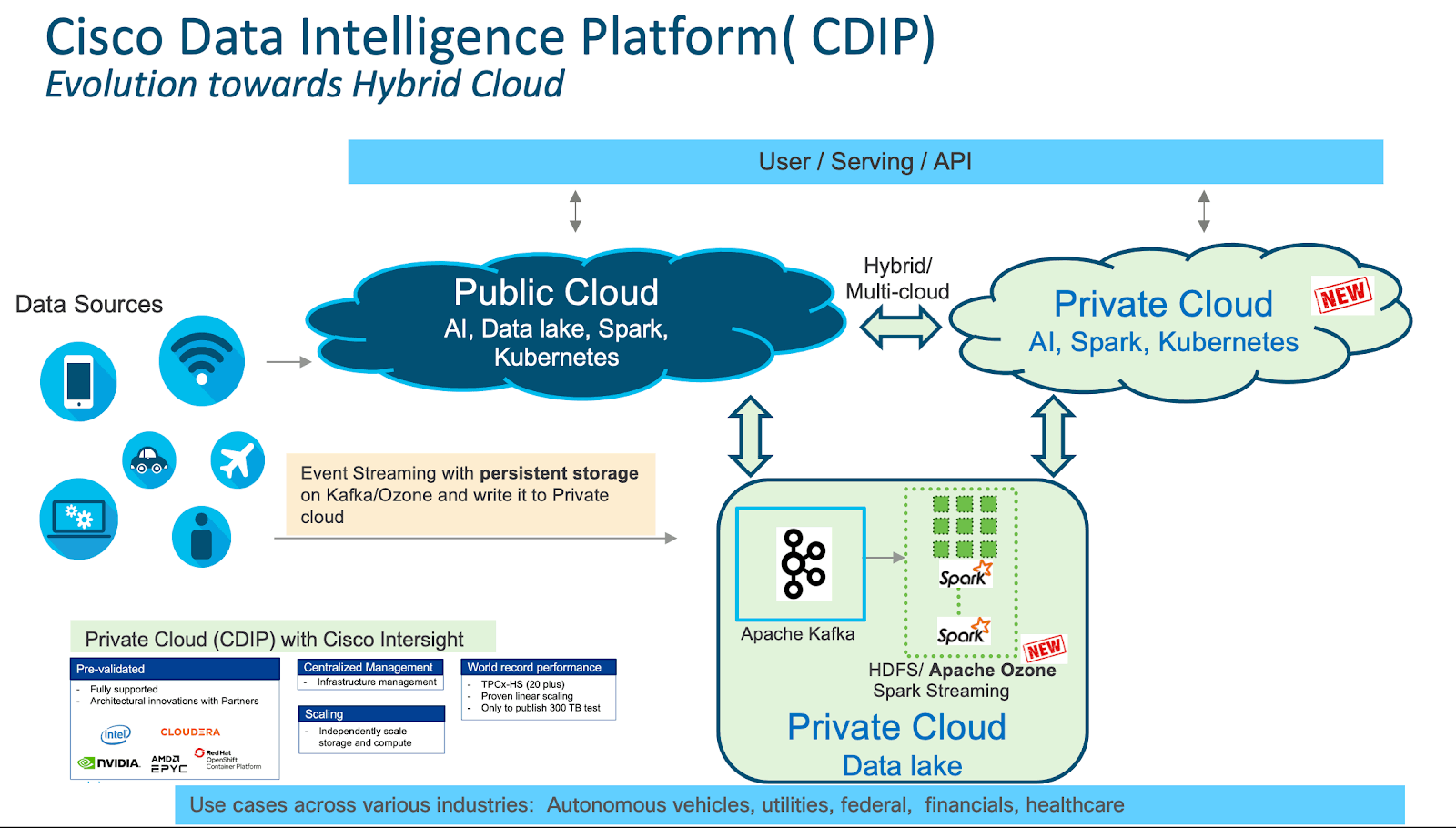
Cisco Data Intelligence Platform
Cisco Data Intelligence Platform (CDIP) is a private cloud architecture which is future-proofed for the next-gen hybrid cloud architecture of a data lake, bringing together big data, AI/compute farm, and storage tiers to work together as a single entity while also being able to scale independently to address the IT issues in the modern data center. This architecture allows for:
- Extremely fast data ingest, and data engineering done at the data lake
- AI compute farm allowing for different types of AI frameworks and compute types (CPU, GPU, FPGA) to work on this data for further analytics
- A storage tier, allowing to grow your data to exabyte scale while on a storage dense system with a lower $/TB providing a better TCO
- Seamlessly scale the architecture to thousands of nodes with a single pane of glass management using Cisco Application Centric Infrastructure (ACI)
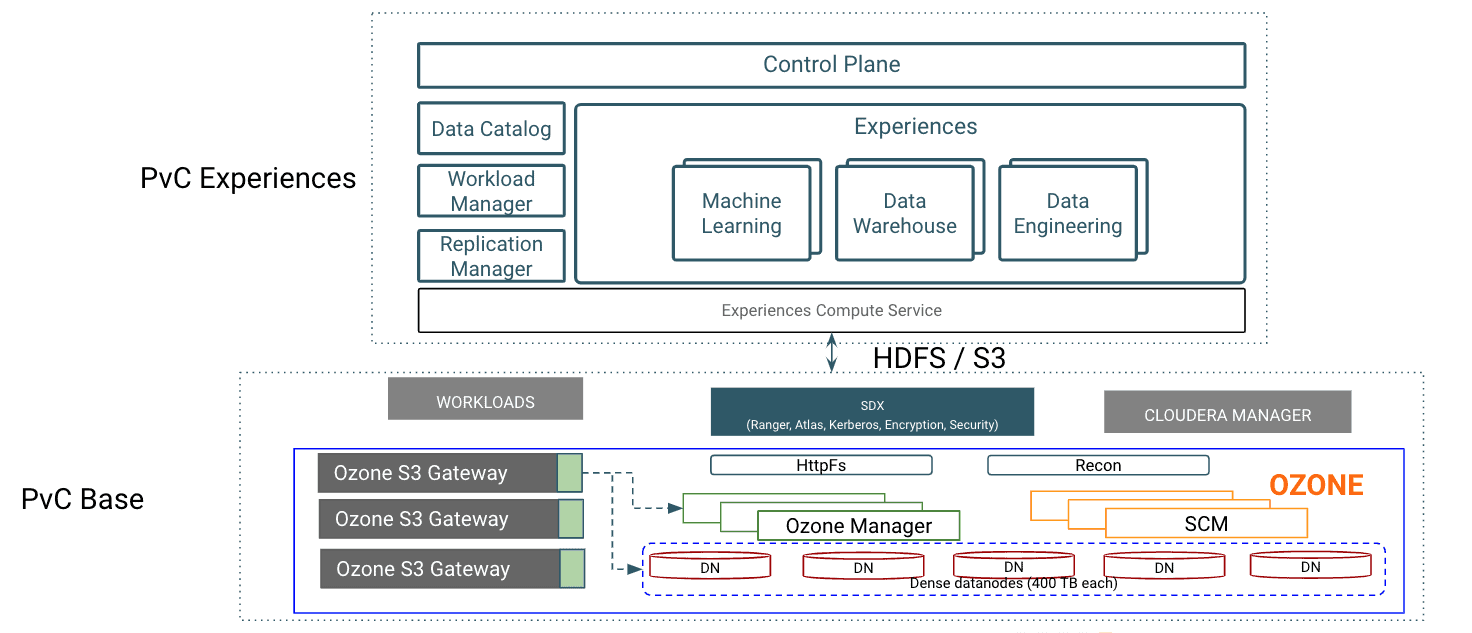
This architecture is the beginning of the convergence of three of the largest open-source initiatives with Hadoop, Kubernetes, and AI/ML largely driven by an impressive software framework and technology introduced by Cloudera Data Platform Private Cloud base and Cloudera Data Platform Private Cloud experiences to crunch big data.
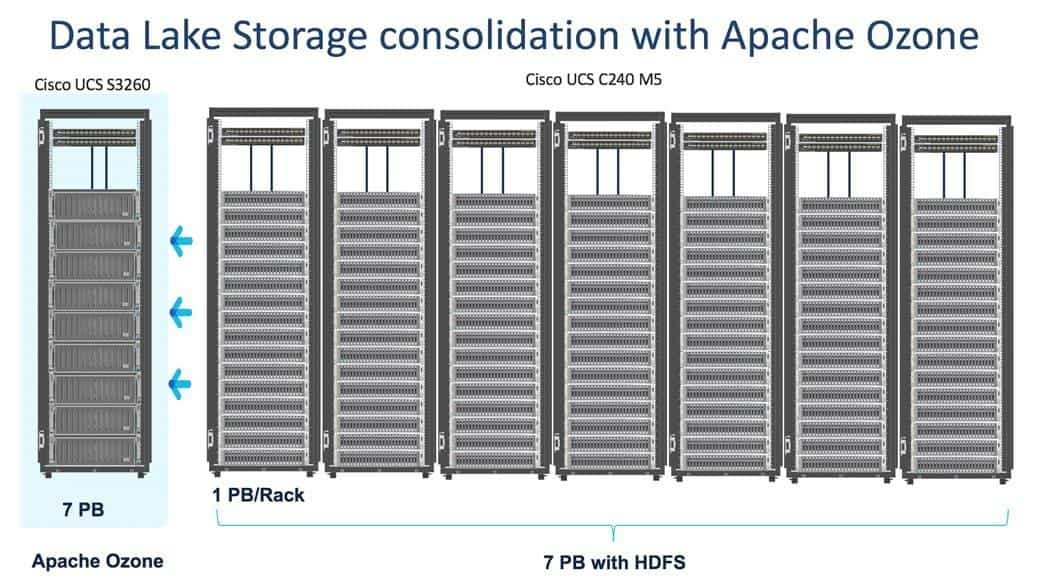
Cisco UCS C240 M5 Rack Servers deliver a highly dense, cost-optimized, on-premises storage with broad infrastructure flexibility for object storage, Hadoop, and Big Data analytics solutions.
This CVD offers customers the ability to consolidate their data lake further, with larger storage per data node. Apache Ozone brings the following cost savings and benefits due to storage consolidation:
- Lower Infrastructure cost
- Lower software licensing and support cost
- Lower lab footprint
- Newer additional use cases with support for HDFS and S3 and billions of objects supporting both large and small files in a similar fashion.
CDIP with Cloudera Data Platform Private Cloud Experiences enables customers to independently scale storage and computing resources while maintaining data locality similar to the prior generation of HDFS. It offers an exabyte scale architecture with low total cost of ownership (TCO) and future-proof architecture with the latest generation of technologies provided by Cloudera.
In addition to that, CDIP offers a single pane of glass management for the entire infrastructure with Cisco Intersight.
You can find the Cisco Validated Design document published here.
Editor's Choice

