

When we announced the GA of Cloudera Data Engineering back in September of last year, a key vision we had was to simplify the automation of data transformation pipelines at scale.
By leveraging Spark on Kubernetes as the foundation along with a first class job management API many of our customers have been able to quickly deploy, monitor and manage the life cycle of their spark jobs with ease. In addition, we allowed users to automate their jobs based on a time-based schedule. Although this could have been done in many ways, we purposely chose Apache Airflow as the core scheduling and orchestration service within DE.
We did this because we wanted to give users the greatest flexibility to define their data pipelines, that go beyond a single spark job and that can have complex sequencing logic with dependencies and triggers. And by being purely python based, Apache Airflow pipelines are accessible to a wide range of users, with a strong open source community.
That’s why we are excited to expand our Apache Airflow-based pipeline orchestration for Cloudera Data Platform (CDP) with the flexibility to define scalable transformations with a combination of Spark and Hive. DE, DW, and ML practitioners that want to orchestrate multi-step data pipelines in the cloud, using a combination of Spark and Hive, can now generate curated datasets for use by downstream applications efficiently and securely. The pipelines are scheduled and orchestrated by a managed Airflow service without the typical administrative cost of setting up and deploying an external scheduling service. It’s included at no extra cost, customers only have to pay for the associated compute infrastructure.
With Airflow based pipelines in DE, customers can now specify their data pipeline using a simple python configuration file. The individual steps can be composed of a mix of hive and spark operators that automatically run jobs on CDW and CDE, respectively, with the underlying security and governance provided by SDX. The sequencing of the jobs can include complex orchestration logic with retries, dependencies, and conditional branching. Now instead of relying on one custom monolithic process, customers can develop modular data transformation steps that are more reusable and easier to debug, which can then be orchestrated with glueing logic at the level of the pipeline configuration instead of being buried within the code. And with CDW we have introduced a new processing mode that allows processing of ETL workloads that mimic Hive on Tez, getting you the best of both worlds — containerization and dedicated resources to process the ETL job.
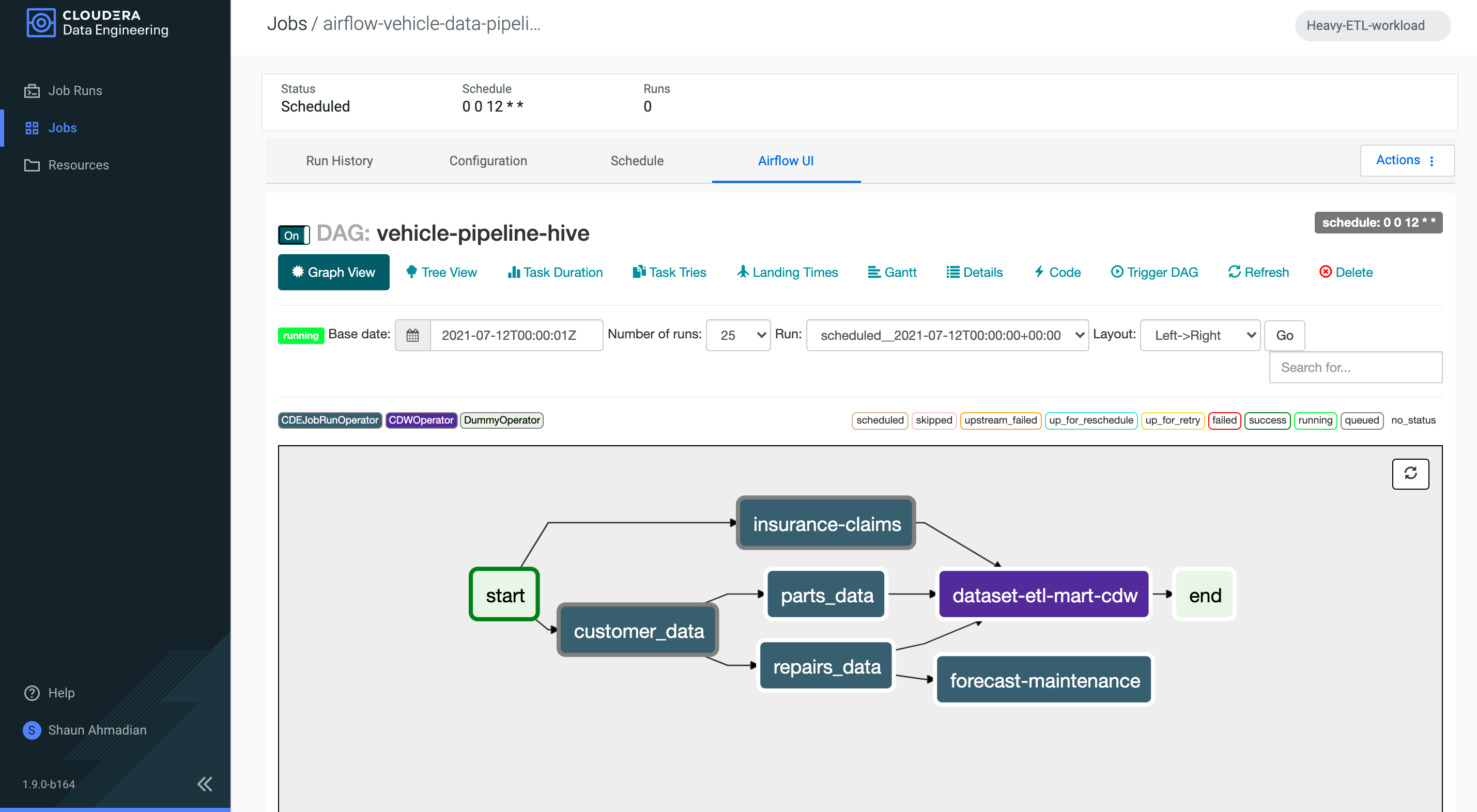
Figure 1: Pipeline composed of Spark and Hive jobs deployed to run within CDE’s managed Apache Airflow service
CDP Airflow operators
Let’s take a common use-case for Business Intelligence reporting. Typically users need to ingest data, transform it into optimal format with quality checks, and optimize querying of the data by visual analytics tool.
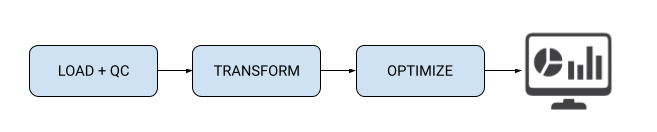
Figure 2: Example BI reporting data pipeline
Each of these steps can correspond to a specific job allowing for modular development. For example, the data load and quality checking can be developed as a single modular job that uses Spark. While the optimize step could be a data mart created leveraging Hive’s materialized view to speed up BI reporting. This modular approach is exactly what Airflow lends itself to, and allows us to take full advantage of the CDP platform.
That’s why we have developed custom Airflow operators to leverage the capabilities of the various analytical experiences within CDP starting with CDE and CDW.
Users can author their Airflow pipeline in their IDE of choice using a simple python configuration file, and then use the same consistent APIs whether through CLI, REST, or UI to submit their pipelines to a DE Virtual Cluster (VC). Users can choose to perform their data transformation operations using two CDP operators – one for running Hive jobs in CDW and the other for running Spark jobs in CDE. Using the new CDP operators is a matter of a few simple lines of configuration that abstract away all the typical complexities such as security while providing key scheduling management capabilities like retries, SLA, and alerts.
Users that have their own self-managed Airflow instances, can also use CDP operators. We recently published our set of CDP operators as open source plugins so that customers of CDP can orchestrate the execution of spark and hive jobs within the CDP platform to reap the cost benefits of autoscaling and security & governance of shared data experience (SDX).
Next
In the future we hope to extend our operators to support other services within CDP such as running machine learning models within CML. And in the last part of the blog series, we will provide a step-by-step example of how to construct and deploy an end-to-end data pipeline using CDE’s managed Airflow service.
Part 1 in the series can be found here.
Editor's Choice

