How to use a Machine Learning Model to Make Predictions on Streaming Data using PySpark
Overview
- Streaming data is a thriving concept in the machine learning space
- Learn how to use a machine learning model (such as logistic regression) to make predictions on streaming data using PySpark
- We’ll cover the basics of Streaming Data and Spark Streaming, and then dive into the implementation part
Introduction
Picture this – every second, more than 8,500 Tweets are sent, more than 900 photos are uploaded on Instagram, more than 4,200 Skype calls are made, more than 78,000 Google Searches happen, and more than 2 million emails are sent (according to Internet Live Stats).
We are generating data at an unprecedented pace and scale right now. What a great time to be working in the data science space! But with great data, comes equally complex challenges.
Primarily – how do we collect data at this scale? How do we ensure that our machine learning pipeline continues to churn out results as soon as the data is generated and collected? These are significant challenges the industry is facing and why the concept of Streaming Data is gaining more traction among organizations.

Adding the ability to handle streaming data will boost your current data science portfolio by quite a margin. It’s a much-needed skill in the industry and will help you land your next data science role if you can master it.
So in this article, we will learn what streaming data is, understand the fundaments of Spark streaming, and then work on an industry-relevant dataset to implement streaming data using Spark.
Table of Contents
- What is Streaming Data?
- Fundamentals of Spark Streaming
- Discretized Streams
- Caching
- Checkpointing
- Shared Variables in Streaming Data
- Accumulator Variable
- Broadcast Variable
- Performing Sentiment Analysis on Streaming Data using PySpark
What is Streaming Data?
We saw the social media figures above – the numbers we are working with are mind-boggling. Can you even begin to imagine what it would take to store all that data? It’s a complex process! So before we dive into the Spark aspect of this article, let’s spend a moment understanding what exactly is streaming data.
Streaming data has no discrete beginning or end. This data is generated every second from thousands of data sources and is required to be processed and analyzed as soon as possible. Quite a lot of streaming data needs to be processed in real-time, such as Google Search results.
We know that some insights are more valuable just after an event happened and they tend to lose their value with time. Think of any sporting event for example – we want to see instant analysis, instant statistical insights, to truly enjoy the game at that moment, right?
For example, let’s say you’re watching a thrilling tennis match between Roger Federer v Novak Djokovic.
The game is tied at 2 sets all and you want to understand the percentages of serves Federer has returned on his backhand as compared to his career average. Would it make sense to see that a few days later or at that moment before the deciding set begins?
Fundamentals of Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable and fault-tolerant stream processing of live data streams.
Let’s understand the different components of Spark Streaming before we jump to the implementation section.
Discretized Streams
Discretized Streams, or DStreams, represent a continuous stream of data. Here, either the data stream is received directly from any source or is received after we’ve done some processing on the original data.
The very first step of building a streaming application is to define the batch duration for the data resource from which we are collecting the data. If the batch duration is 2 seconds, then the data will be collected every 2 seconds and stored in an RDD. And the chain of continuous series of these RDDs is a DStream which is immutable and can be used as a distributed dataset by Spark.
I would highly recommend you go through this article to get a better understanding of RDDs – Comprehensive Introduction to Spark: RDDs.

Think of a typical data science project. During the data pre-processing stage, we need to transform variables, including converting categorical ones into numeric, creating bins, removing the outliers and lots of other things. Spark maintains a history of all the transformations that we define on any data. So, whenever any fault occurs, it can retrace the path of transformations and regenerate the computed results again.
We want our Spark application to run 24 x 7 and whenever any fault occurs, we want it to recover as soon as possible. But while working with data at a massive scale, Spark needs to recompute all the transformations again in case of any fault. This, as you can imagine, can be quite expensive.
Caching
Here’s one way to deal with this challenge. We can store the results we have calculated (cached) temporarily to maintain the results of the transformations that are defined on the data. This way, we don’t have to recompute those transformations again and again when any fault occurs.
DStreams allow us to keep the streaming data in memory. This is helpful when we want to compute multiple operations on the same data.
Checkpointing
Caching is extremely helpful when we use it properly but it requires a lot of memory. And not everyone has hundreds of machines with 128 GB of RAM to cache everything.
This is where the concept of Checkpointing will help us.
Checkpointing is another technique to keep the results of the transformed dataframes. It saves the state of the running application from time to time on any reliable storage like HDFS. However, it is slower and less flexible than caching.
We can use checkpoints when we have streaming data. The transformation result depends upon previous transformation results and needs to be preserved in order to use it. We also checkpoint metadata information, like what was the configuration that was used to create the streaming data and the results of a set of DStream operations, among other things.
Shared Variables in Streaming Data
There are times when we need to define functions like map, reduce or filter for our Spark application that has to be executed on multiple clusters. The variables used in this function are copied to each of the machines (clusters).
Here, each cluster has a different executor and we want something that can give us a relation between these variables.
For example, let’s assume our Spark application is running on 100 different clusters capturing Instagram images posted by people from different countries. We need a count of a particular tag that was mentioned in a post.
Now, each cluster’s executor will calculate the results of the data present on that particular cluster. But we need something that helps these clusters communicate so we can get the aggregated result. In Spark, we have shared variables that allow us to overcome this issue.
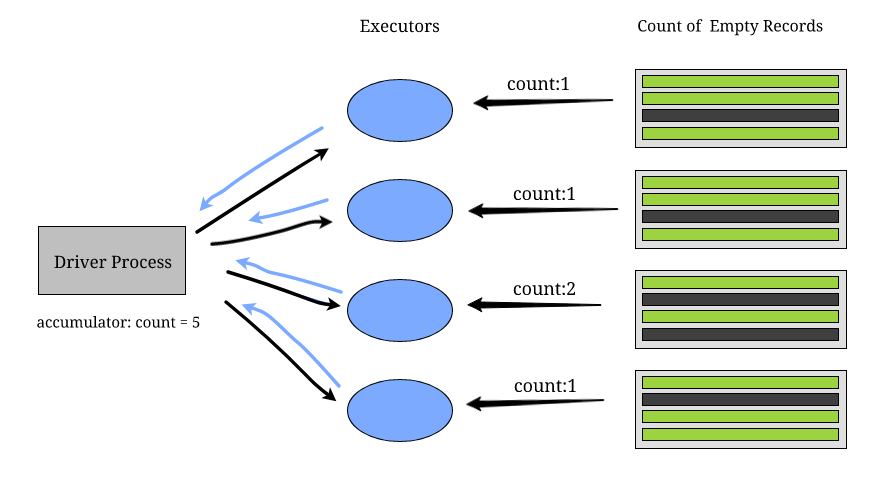
Accumulator Variable
Use cases like the number of times an error occurs, the number of blank logs, the number of times we receive a request from a particular country – all of these can be solved using accumulators.
The executor on each cluster sends data back to the driver process to update the values of the accumulator variables. Accumulators are applicable only to the operations that are associative and commutative. For example, sum and maximum will work, whereas the mean will not.
Broadcast Variable
When we’re working with location data, such as mappings of city names and ZIP codes – these are fixed variables, right? Now, if every time a particular transformation on any cluster requires this type of data, we do not need to send a request to the driver as it will be too expensive.
Instead, we can store a copy of this data on each cluster. These types of variables are known as Broadcast variables.
Broadcast variables allow the programmer to keep a read-only variable cached on each machine. Usually, Spark automatically distributes broadcast variables using efficient broadcast algorithms but we can also define them if we have tasks that require the same data for multiple stages.

Performing Sentiment Analysis on Streaming Data using PySpark
Time to fire up your favorite IDE! Let’s get coding in this section and understand Streaming Data in a practical manner.
Understanding the Problem Statement
We’ll work with a real-world dataset in this section. Our aim is to detect hate speech in Tweets. For the sake of simplicity, we say a Tweet contains hate speech if it has a racist or sexist sentiment associated with it.
So, the task is to classify racist or sexist Tweets from other Tweets. We will use a training sample of Tweets and labels, where label ‘1’ denotes that a Tweet is racist/sexist and label ‘0’ denotes otherwise.
 Source: TechCrunch
Source: TechCrunch
Why is this a relevant project? Because social media platforms receive mammoth streaming data in the form of comments and status updates. This project will help us moderate what is being posted publicly.
You can check out the problem statement in more detail here – Practice Problem: Twitter Sentiment Analysis. Let’s begin!
Setting up the Project Workflow
- Model Building: We will build a Logistic Regression Model pipeline to classify whether the tweet contains hate speech or not. Here, our focus is not to build a very accurate classification model but to see how to use any model and return results on streaming data
- Initialize Spark Streaming Context: Once the model is built, we need to define the hostname and port number from where we get the streaming data
- Stream Data: Next, we will add the tweets from the netcat server from the defined port, and the Spark Streaming API will receive the data after a specified duration
- Predict and Return Results: Once we receive the tweet text, we pass the data into the machine learning pipeline we created and return the predicted sentiment from the model
Here’s a neat illustration of our workflow:

Training the Data for Building a Logistic Regression Model
We have data about Tweets in a CSV file mapped to a label. We will use a logistic regression model to predict whether the tweet contains hate speech or not. If yes, then our model will predict the label as 1 (else 0). You can refer to this article “PySpark for Beginners” to set up the Spark environment.
You can download the dataset and code here.
First, we need to define the schema of the CSV file. Otherwise, Spark will consider the data type of each column as string. Read the data and check if the schema is as defined or not:


Defining the Stages of our Machine Learning Pipeline
Now that we have the data in a Spark dataframe, we need to define the different stages in which we want to transform the data and then use it to get the predicted label from our model.
In the first stage, we will use the RegexTokenizer to convert Tweet text into a list of words. Then, we will remove the stop words from the word list and create word vectors. In the final stage, we will use these word vectors to build a logistic regression model and get the predicted sentiments.
Remember – our focus is not on building a very accurate classification model but rather to see how can we use a predictive model to get the results on streaming data.
You can refer to this article – “Comprehensive Hands-on Guide to Twitter Sentiment Analysis” – to build a more accurate and robust text classification model. And you can also read more about building Spark Machine Learning Pipelines here: Want to Build Machine Learning Pipelines? A Quick Introduction using PySpark.
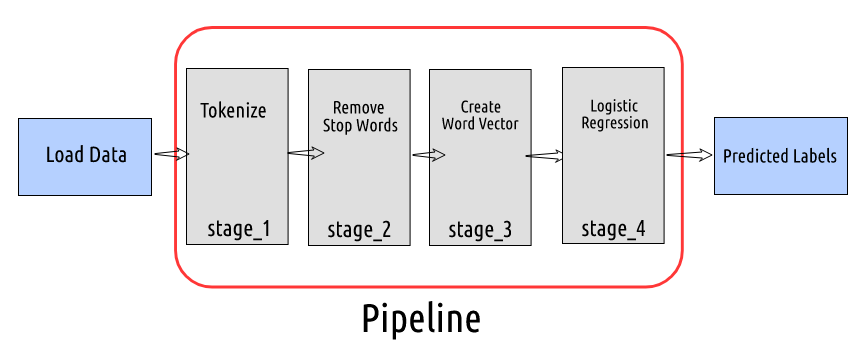
Setup our Machine Learning Pipeline
Let’s add the stages in the Pipeline object and we will then perform these transformations in order. Fit the pipeline with the training dataset and now, whenever we have a new Tweet, we just need to pass that through the pipeline object and transform the data to get the predictions:
Stream Data and Return Results
Let’s say we receive hundreds of comments per second and we want to keep the platform clean by blocking the users who post comments that contain hate speech. So, whenever we receive the new text, we will pass that into the pipeline and get the predicted sentiment.
We will define a function get_prediction which will remove the blank sentences and create a dataframe where each row contains a Tweet.
So, initialize the Spark Streaming context and define a batch duration of 3 seconds. This means that we will do predictions on data that we receive every 3 seconds:
Run the program in one terminal and use Netcat (a utility tool that can be used to send data to the defined hostname and port number). You can start the TCP connection using this command:
nc -lk port_number
Finally, type the text in the second terminal and you will get the predictions in real-time in the other terminal:
Perfect!
End Notes
Streaming data is only going to increase in the coming years so you should really started getting familiar with this topic. Remember, data science isn’t just about building models – there’s an entire pipeline that needs to be taken care of.
This article covered the fundamentals of Spark Streaming and how to implement it on a real-world dataset. I encourage you to take up another dataset or scrape live data and implement what we just covered (you can try out a different model as well).
I look forward to hearing your feedback on this article, and your thoughts, in the comments section below.








Hi! The project seems interesting. Is there any alternative to netcap ? and what should be the port number ?
If you are using Windows then you can also use MobaXterm. It has almost similar commands like netcat.
Machine learning is the next big thing. In fact, with proper implementation, this will allow the machines and devices to work with the same ingenuity as a human.