AWS Big Data Blog
Introducing Amazon MSK as a source for Amazon OpenSearch Ingestion
Ingesting a high volume of streaming data has been a defining characteristic of operational analytics workloads with Amazon OpenSearch Service. Many of these workloads involve either self-managed Apache Kafka or Amazon Managed Streaming for Apache Kafka (Amazon MSK) to satisfy their data streaming needs. Consuming data from Amazon MSK and writing to OpenSearch Service has been a challenge for customers. AWS Lambda, custom code, Kafka Connect, and Logstash have been used for ingesting this data. These methods involve tools that must be built and maintained. In this post, we introduce Amazon MSK as a source to Amazon OpenSearch Ingestion, a serverless, fully managed, real-time data collector for OpenSearch Service that makes this ingestion even easier.
Solution overview
The following diagram shows the flow from data sources to Amazon OpenSearch Service.
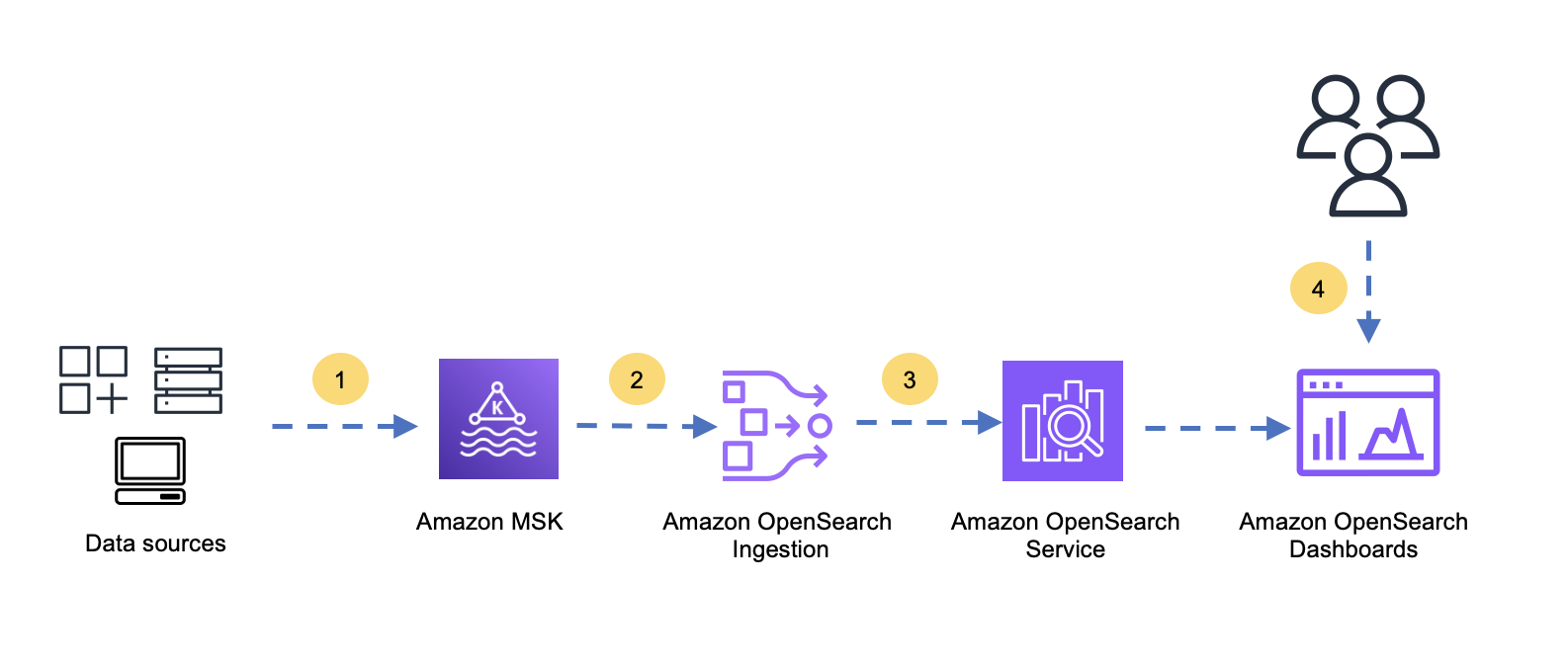
The flow contains the following steps:
- Data sources produce data and send that data to Amazon MSK
- OpenSearch Ingestion consumes the data from Amazon MSK.
- OpenSearch Ingestion transforms, enriches, and writes the data into OpenSearch Service.
- Users search, explore, and analyze the data with OpenSearch Dashboards.
Prerequisites
You will need a provisioned MSK cluster created with appropriate data sources. The sources, as producers, write data into Amazon MSK. The cluster should be created with the appropriate Availability Zone, storage, compute, security and other configurations to suit your workload needs. To provision your MSK cluster and have your sources producing data, see Getting started using Amazon MSK.
As of this writing, OpenSearch Ingestion supports Amazon MSK provisioned, but not Amazon MSK Serverless. However, OpenSearch Ingestion can reside in the same or different account where Amazon MSK is present. OpenSearch Ingestion uses AWS PrivateLink to read data, so you must turn on multi-VPC connectivity on your MSK cluster. For more information, see Amazon MSK multi-VPC private connectivity in a single Region. OpenSearch Ingestion can write data to Amazon Simple Storage Service (Amazon S3), provisioned OpenSearch Service, and Amazon OpenSearch Service. In this solution, we use a provisioned OpenSearch Service domain as a sink for OSI. Refer to Getting started with Amazon OpenSearch Service to create a provisioned OpenSearch Service domain. You will need appropriate permission to read data from Amazon MSK and write data to OpenSearch Service. The following sections outline the required permissions.
Permissions required
To read from Amazon MSK and write to Amazon OpenSearch Service, you need to create a an AWS Identity and Access Management (IAM) role used by Amazon OpenSearch Ingestion. In this post we use a role called pipeline-Role for this purpose. To create this role please see Creating IAM roles.
Reading from Amazon MSK
OpenSearch Ingestion will need permission to create a PrivateLink connection and other actions that can be performed on your MSK cluster. Edit your MSK cluster policy to include the following snippet with appropriate permissions. If your OpenSearch Ingestion pipeline resides in an account different from your MSK cluster, you will need a second section to allow this pipeline. Use proper semantic conventions when providing the cluster, topic, and group permissions and remove the comments from the policy before using.
Edit the pipeline role’s inline policy to include the following permissions. Ensure that you have removed the comments before using the policy.
Writing to OpenSearch Service
In this section, you provide the pipeline role with necessary permissions to write to OpenSearch Service. As a best practice, we recommend using fine-grained access control in OpenSearch Service. Use OpenSearch dashboards to map a pipeline role to an appropriate backend role. For more information on mapping roles to users, see Managing permissions. For example, all_access is a built-in role that grants administrative permission to all OpenSearch functions. When deploying to a production environment, ensure that you use a role with enough permissions to write to your OpenSearch domain.

Creating OpenSearch Ingestion pipelines
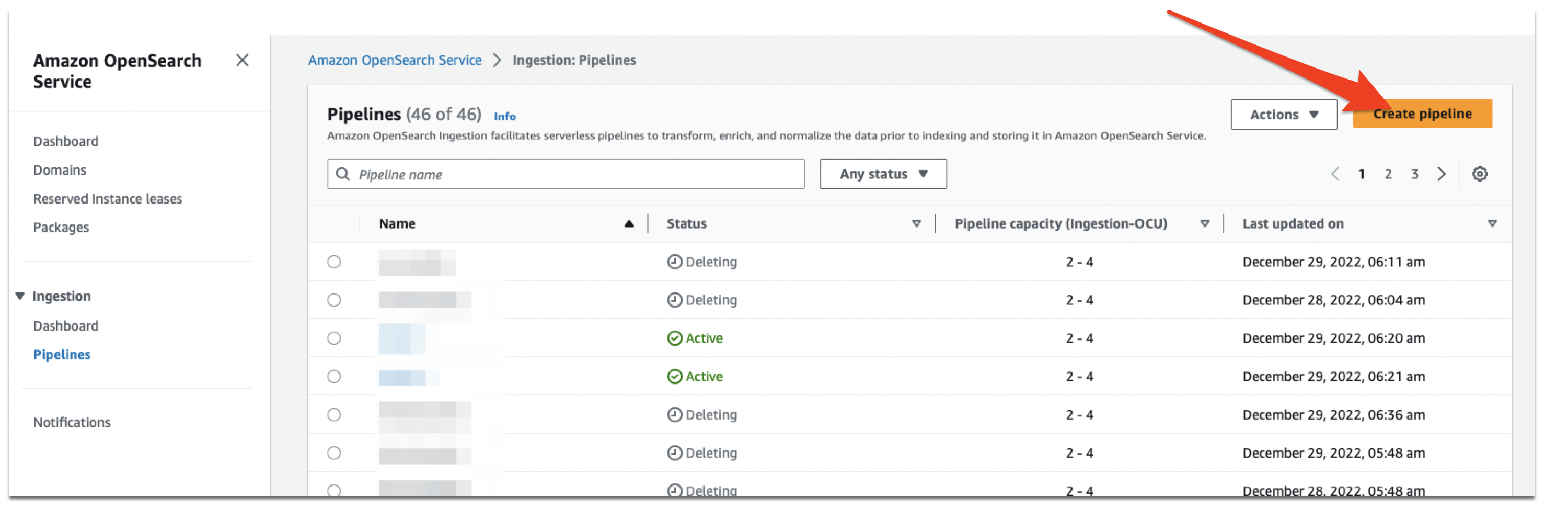
The pipeline role now has the correct set of permissions to read from Amazon MSK and write to OpenSearch Service. Navigate to the OpenSearch Service console, choose Pipelines, then choose Create pipeline.
Choose a suitable name for the pipeline. and se the pipeline capacity with appropriate minimum and maximum OpenSearch Compute Unit (OCU). Then choose ‘AWS-MSKPipeline’ from the dropdown menu as shown below.
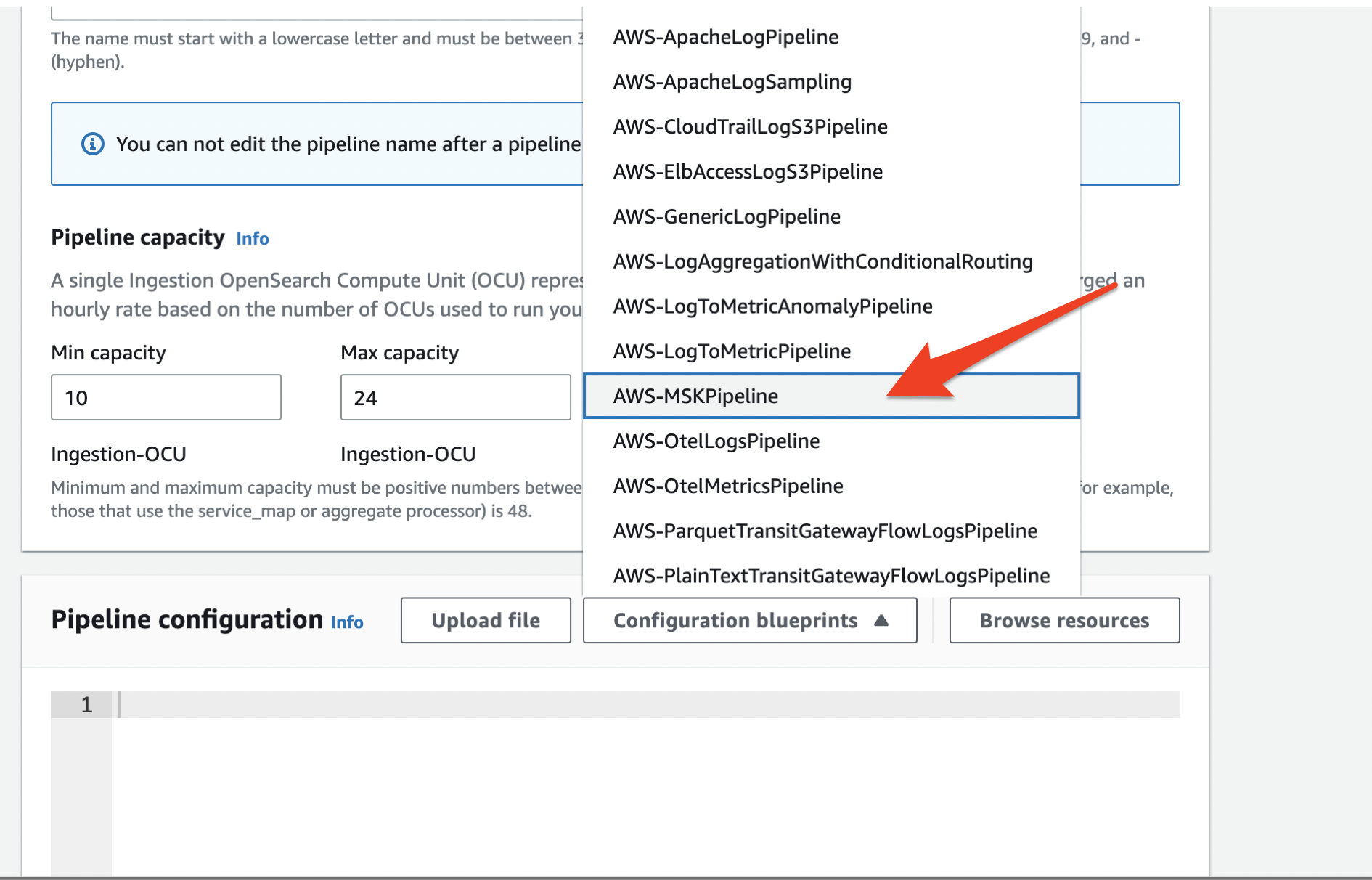
Use the provided template to fill in all the required fields. The snippet in the following section shows the fields that needs to be filled in red.
Configuring Amazon MSK source
The following sample configuration snippet shows every setting you need to get the pipeline running:
We use the following parameters:
- acknowledgements – Set to
truefor OpenSearch Ingestion to ensure that the data is delivered to the sinks before committing the offsets in Amazon MSK. The default value is set to false. - name – This specifies topic OpenSearch Ingestion can read from. You can read a maximum of four topics per pipeline.
- group_id – This parameter specifies that the pipeline is part of the consumer group. With this setting, a single consumer group can be scaled to as many pipelines as needed for very high throughput.
- serde_format – Specifies a deserialization method to be used for the data read from Amazon MSK. The options are JSON and plaintext.
- AWS sts_role_arn and OpenSearch sts_role_arn – Specifies the role OpenSearch Ingestion uses for reading and writing. Specify the ARN of the role you created from the last section. OpenSearch Ingestion currently uses the same role for reading and writing.
- MSK arn – Specifies the MSK cluster to consume data from.
- OpenSearch host and index – Specifies the OpenSearch domain URL and where the index should write.
When you have configured the Kafka source, choose the network access type and log publishing options. Public pipelines do not involve PrivateLink and they will not incur a cost associated with PrivateLink. Choose Next and review all configurations. When you are satisfied, choose Create pipeline.
Log in to OpenSearch Dashboards to see your indexes and search the data.
Recommended compute units (OCUs) for the MSK pipeline
Each compute unit has one consumer per topic. Brokers will balance partitions among these consumers for a given topic. However, when the number of partitions is greater than the number of consumers, Amazon MSK will host multiple partitions on every consumer. OpenSearch Ingestion has built-in auto scaling to scale up or down based on CPU usage or number of pending records in the pipeline. For optimal performance, partitions should be distributed across many compute units for parallel processing. If topics have a large number of partitions, for example, more than 96 (maximum OCUs per pipeline), we recommend configuring a pipeline with 1–96 OCUs because it will auto scale as needed. If a topic has a low number of partitions, for example, less than 96, then keep the maximum compute unit to same as the number of partitions. When pipeline has more than one topic, user can pick a topic with highest number of partitions as a reference to configure maximum computes units. By adding another pipeline with a new set of OCUs to the same topic and consumer group, you can scale the throughput almost linearly.
Clean up
To avoid future charges, clean up any unused resources from your AWS account.
Conclusion
In this post, you saw how to use Amazon MSK as a source for OpenSearch Ingestion. This not only addresses the ease of data consumption from Amazon MSK, but it also relieves you of the burden of self-managing and manually scaling consumers for varying and unpredictable high-speed, streaming operational analytics data. Please refer to the ‘sources’ list under ‘supported plugins’ section for exhaustive list of sources from which you can ingest data.
About the authors
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
 Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focusses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large scale distributed systems and cloud-native technologies and is based out of Seattle, Washington.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focusses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large scale distributed systems and cloud-native technologies and is based out of Seattle, Washington.
 Raj Sharma is a Sr. SDM with Amazon OpenSearch Service. He builds large-scale distributed applications and solutions. Raj is interested in the topics of Analytics, databases, networking and security, and is based out of Palo Alto, California.
Raj Sharma is a Sr. SDM with Amazon OpenSearch Service. He builds large-scale distributed applications and solutions. Raj is interested in the topics of Analytics, databases, networking and security, and is based out of Palo Alto, California.