AWS Big Data Blog
Implement data warehousing solution using dbt on Amazon Redshift
Amazon Redshift is a cloud data warehousing service that provides high-performance analytical processing based on a massively parallel processing (MPP) architecture. Building and maintaining data pipelines is a common challenge for all enterprises. Managing the SQL files, integrating cross-team work, incorporating all software engineering principles, and importing external utilities can be a time-consuming task that requires complex design and lots of preparation.
dbt (DataBuildTool) offers this mechanism by introducing a well-structured framework for data analysis, transformation and orchestration. It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries. This mechanism allows developers to focus on preparing the SQL files per the business logic, and the rest is taken care of by dbt.
In this post, we look into an optimal and cost-effective way of incorporating dbt within Amazon Redshift. We use Amazon Elastic Container Registry (Amazon ECR) to store our dbt Docker images and AWS Fargate as an Amazon Elastic Container Service (Amazon ECS) task to run the job.
How does the dbt framework work with Amazon Redshift?
dbt has an Amazon Redshift adapter module named dbt-redshift that enables it to connect and work with Amazon Redshift. All the connection profiles are configured within the dbt profiles.yml file. In an optimal environment, we store the credentials in AWS Secrets Manager and retrieve them.
The following code shows the contents of profile.yml:
The following diagram illustrates the key components of the dbt framework:

The primary components are as follows:
- Models – These are written as a SELECT statement and saved as a .sql file. All the transformation queries can be written here which can be materialized as a table or view. The table refresh can be full or incremental based on the configuration. For more information, refer SQL models.
- Snapshots – These implements type-2 slowly changing dimensions (SCDs) over mutable source tables. These SCDs identify how a row in a table changes over time.
- Seeds – These are CSV files in your dbt project (typically in your seeds directory), which dbt can load into your data warehouse using the
dbt seedcommand. - Tests – These are assertions you make about your models and other resources in your dbt project (such as sources, seeds, and snapshots). When you run
dbt test, dbt will tell you if each test in your project passes or fails. - Macros – These are pieces of code that can be reused multiple times. They are analogous to “functions” in other programming languages, and are extremely useful if you find yourself repeating code across multiple models.
These components are stored as .sql files and are run by dbt CLI commands. During the run, dbt creates a Directed Acyclic Graph (DAG) based on the internal reference between the dbt components. It uses the DAG to orchestrate the run sequence accordingly.
Multiple profiles can be created within the profiles.yml file, which dbt can use to target different Redshift environments while running. For more information, refer to Redshift set up.
Solution overview
The following diagram illustrates our solution architecture.
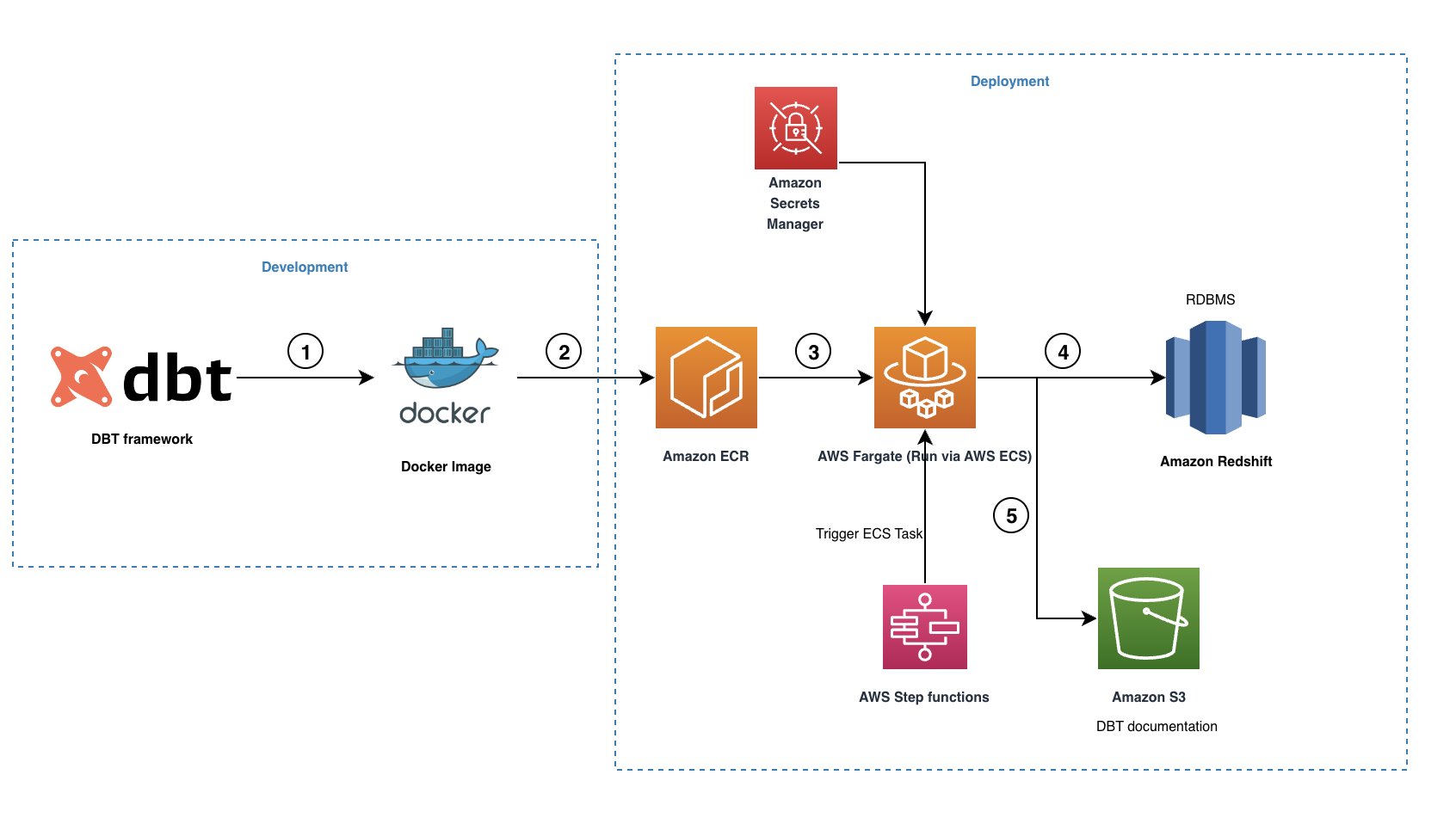
The workflow contains the following steps:
- The open source dbt-redshift connector is used to create our dbt project including all the necessary models, snapshots, tests, macros and profiles.
- A Docker image is created and pushed to the ECR repository.
- The Docker image is run by Fargate as an ECS task triggered via AWS Step Functions. All the Amazon Redshift credentials are stored in Secrets Manager, which is then used by the ECS task to connect with Amazon Redshift.
- During the run, dbt converts all the models, snapshots, tests and macros to Amazon Redshift compliant SQL statements and it orchestrates the run based on the internal data lineage graph maintained. These SQL commands are run directly on the Redshift cluster and therefore the workload is pushed to Amazon Redshift directly.
- When the run is complete, dbt will create a set of HTML and JSON files to host the dbt documentation, which describes the data catalog, compiled SQL statements, data lineage graph, and more.
Prerequisites
You should have the following prerequisites:
- A good understanding of the dbt principles and implementation steps.
- An AWS account with user role permission to access the AWS services used in this solution.
- Security groups for Fargate to access the Redshift cluster and Secrets Manager from Amazon ECS.
- A Redshift cluster. For creation instructions, refer to Create a cluster.
- An ECR repository: For instructions, refer to Creating a private repository
- A Secrets Manager secret containing all the credentials for connecting to Amazon Redshift. This includes the host, port, database name, user name, and password. For more information, refer to Create an AWS Secrets Manager database secret.
- An Amazon Simple Storage (Amazon S3) bucket to host documentation files.
Create a dbt project
We are using dbt CLI so all commands are run in the command line. Therefore, install pip if not already installed. Refer to installation for more information.
To create a dbt project, complete the following steps:
- Install dependent dbt packages:
pip install dbt-redshift - Initialize a dbt project using the
dbt init <project_name>command, which creates all the template folders automatically. - Add all the required DBT artifacts.
Refer to the dbt-redshift-etlpattern repo which includes a reference dbt project. For more information about building projects, refer to About dbt projects.
In the reference project, we have implemented the following features:
- SCD type 1 using incremental models
- SCD type 2 using snapshots
- Seed look-up files
- Macros for adding reusable code in the project
- Tests for analyzing inbound data
The Python script is prepared to fetch the credentials required from Secrets Manager for accessing Amazon Redshift. Refer to the export_redshift_connection.py file.
- Prepare the
run_dbt.shscript to run the dbt pipeline sequentially. This script is placed in the root folder of the dbt project as shown in sample repo.
- Create a Docker file in the parent directory of the dbt project folder. This step builds the image of the dbt project to be pushed to the ECR repository.
Upload the image to Amazon ECR and run it as an ECS task
To push the image to the ECR repository, complete the following steps:
- Retrieve an authentication token and authenticate your Docker client to your registry:
- Build your Docker image using the following command:
- After the build is complete, tag your image so you can push it to the repository:
- Run the following command to push the image to your newly created AWS repository:
- On the Amazon ECS console, create a cluster with Fargate as an infrastructure option.
- Provide your VPC and subnets as required.
- After you create the cluster, create an ECS task and assign the created dbt image as the task definition family.
- In the networking section, choose your VPC, subnets, and security group to connect with Amazon Redshift, Amazon S3 and Secrets Manager.
This task will trigger the run_dbt.sh pipeline script and run all the dbt commands sequentially. When the script is complete, we can see the results in Amazon Redshift and the documentation files pushed to Amazon S3.
- You can host the documentation via Amazon S3 static website hosting. For more information, refer to Hosting a static website using Amazon S3.
- Finally, you can run this task in Step Functions as an ECS task to schedule the jobs as required. For more information, refer to Manage Amazon ECS or Fargate Tasks with Step Functions.
The dbt-redshift-etlpattern repo now has all the code samples required.
Cost for executing dbt jobs in AWS Fargate as an Amazon ECS task with minimal operational requirements would take around $1.5 (cost_link) per month.
Clean up
Complete the following steps to clean up your resources:
- Delete the ECS Cluster you created.
- Delete the ECR repository you created for storing the image files.
- Delete the Redshift Cluster you created.
- Delete the Redshift Secrets stored in Secrets Manager.
Conclusion
This post covered the basic implementation of using dbt with Amazon Redshift in a cost-efficient way by using Fargate in Amazon ECS. We described the key infrastructure and configuration set-up with a sample project. This architecture can help you take advantage of the benefits of having a dbt framework to manage your data warehouse platform in Amazon Redshift.
For more information about dbt macros and models for Amazon Redshift internal operation and maintenance, refer to the following GitHub repo. In subsequent post, we’ll explore the traditional extract, transform, and load (ETL) patterns that you can implement using the dbt framework in Amazon Redshift. Test this solution in your account and provide feedback or suggestions in the comments.
About the Authors
 Seshadri Senthamaraikannan is a data architect with AWS professional services team based in London, UK. He is well experienced and specialised in Data Analytics and works with customers focusing on building innovative and scalable solutions in AWS Cloud to meet their business goals. In his spare time, he enjoys spending time with his family and play sports.
Seshadri Senthamaraikannan is a data architect with AWS professional services team based in London, UK. He is well experienced and specialised in Data Analytics and works with customers focusing on building innovative and scalable solutions in AWS Cloud to meet their business goals. In his spare time, he enjoys spending time with his family and play sports.
 Mohamed Hamdy is a Senior Big Data Architect with AWS Professional Services based in London, UK. He has over 15 years of experience architecting, leading, and building data warehouses and big data platforms. He helps customers develop big data and analytics solutions to accelerate their business outcomes through their cloud adoption journey. Outside of work, Mohamed likes travelling, running, swimming and playing squash.
Mohamed Hamdy is a Senior Big Data Architect with AWS Professional Services based in London, UK. He has over 15 years of experience architecting, leading, and building data warehouses and big data platforms. He helps customers develop big data and analytics solutions to accelerate their business outcomes through their cloud adoption journey. Outside of work, Mohamed likes travelling, running, swimming and playing squash.