AWS Big Data Blog
Use Amazon Athena to query data stored in Google Cloud Platform
As customers accelerate their migrations to the cloud and transform their businesses, some find themselves in situations where they have to manage data analytics in a multi-cloud environment, such as acquiring a company that runs on a different cloud provider. Customers who use multi-cloud environments often face challenges in data access and compatibility that can create blockades and slow down productivity.
When managing multi-cloud environments, customers must look for services that address these gaps through features providing interoperability across clouds. With the release of the Amazon Athena data source connector for Google Cloud Storage (GCS), you can run queries within AWS to query data in Google Cloud Storage, which can be stored in relational, non-relational, object, and custom data sources, whether that be Parquet or comma-separated value (CSV) format. Athena provides the connectivity and query interface and can easily be plugged into other AWS services for downstream use cases such as interactive analysis and visualizations. Some examples include AWS data analytics services such as AWS Glue for data integration, Amazon QuickSight for business intelligence (BI), as well as third-party software and services from AWS Marketplace.
This post demonstrates how to use Athena to run queries on Parquet or CSV files in a GCS bucket.
Solution overview
The following diagram illustrates the solution architecture.

The Athena Google Cloud Storage connector uses both AWS and Google Cloud Platform (GCP), so we will be referencing both cloud providers in the architecture diagram.
We use the following AWS services in this solution:
- Amazon Athena – A serverless interactive analytics service. We use Athena to run queries on data stored on Google Cloud Storage.
- AWS Lambda – A serverless compute service that is event driven and manages the underlying resources for you. We deploy a Lambda function data source connector to connect AWS with Google Cloud Provider.
- AWS Secrets Manager – A secrets management service that helps protect access to your applications and services. We reference the secret in Secrets Manager in the Lambda function so we can run a query on AWS and it can access the data stored on Google Cloud Provider.
- AWS Glue – A serverless data analytics service for data discovery, preparation, and integration. We create an AWS Glue database and table to point to the correct bucket and files within Google Cloud Storage.
- Amazon Simple Storage Service (Amazon S3) – An object storage service that stores data as objects within buckets. We create an S3 bucket to store data that exceeds the Lambda function’s response size limits.
The Google Cloud Platform portion of the architecture contains a few services as well:
- Google Cloud Storage – A managed service for storing unstructured data. We use Google Cloud Storage to store data within a bucket that will be used in a query from Athena, and we upload a CSV file directly to the GCS bucket.
- Google Cloud Identity and Access Management (IAM) – The central source to control and manage visibility for cloud resources. We use Google Cloud IAM to create a service account and generate a key that will allow AWS to access GCP. We create a key with the service account, which is uploaded to Secrets Manager.
Prerequisites
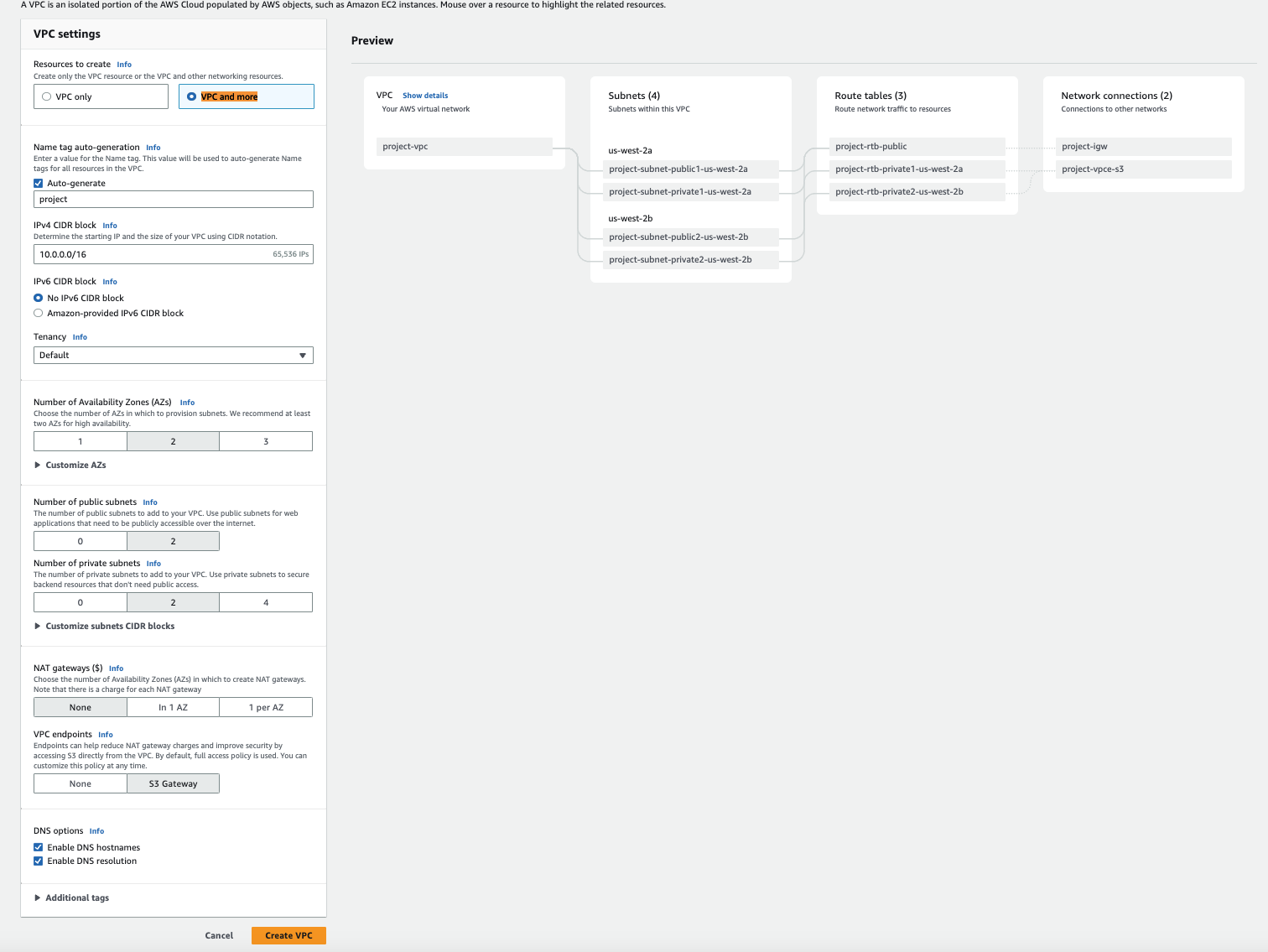
For this post, we create a VPC and security group that will be used in conjunction with the GCP connector. For complete steps, refer to Creating a VPC for a data source connector. The first step is to create the VPC using Amazon Virtual Private Cloud (Amazon VPC), as shown in the following screenshot.
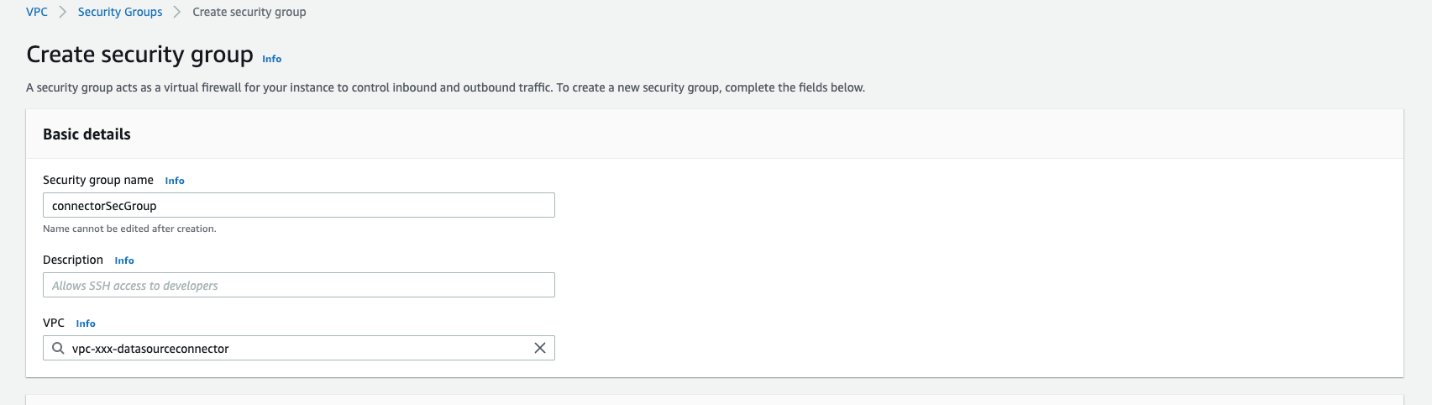
Then we create a security group for the VPC, as shown in the following screenshot.
For more information about the prerequisites, refer to Amazon Athena Google Cloud Storage connector. Additionally, there are tables that highlight the specific data types that can be used such as CSV and Parquet files. There are also required permissions to run the solution.
Google Cloud Platform configuration
To begin, you must have either CSV or Parquet files stored within a GCS bucket. To create the bucket, refer to Create buckets. Make sure to note the bucket name—it will be referenced in a later step. After you create the bucket, upload your objects to the bucket. For instructions, refer to Upload objects from a filesystem.
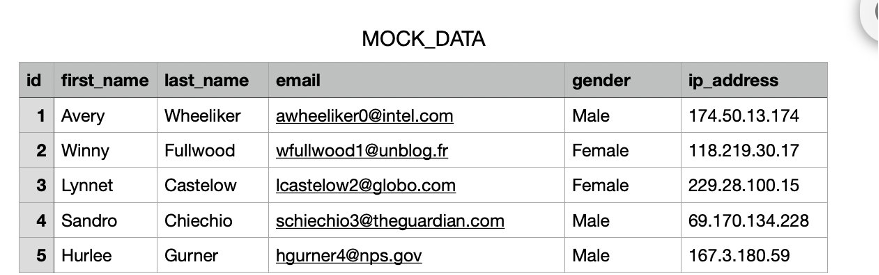
The CSV data used in this example came from Mockaroo, which generated random test data as shown in the following screenshot. In this example, we use a CSV file, but you can also use Parquet files.
Additionally, you must create a service account to generate a key pair within Google Cloud IAM, which will be uploaded to Secrets Manager. For full instructions, refer to Create service accounts.
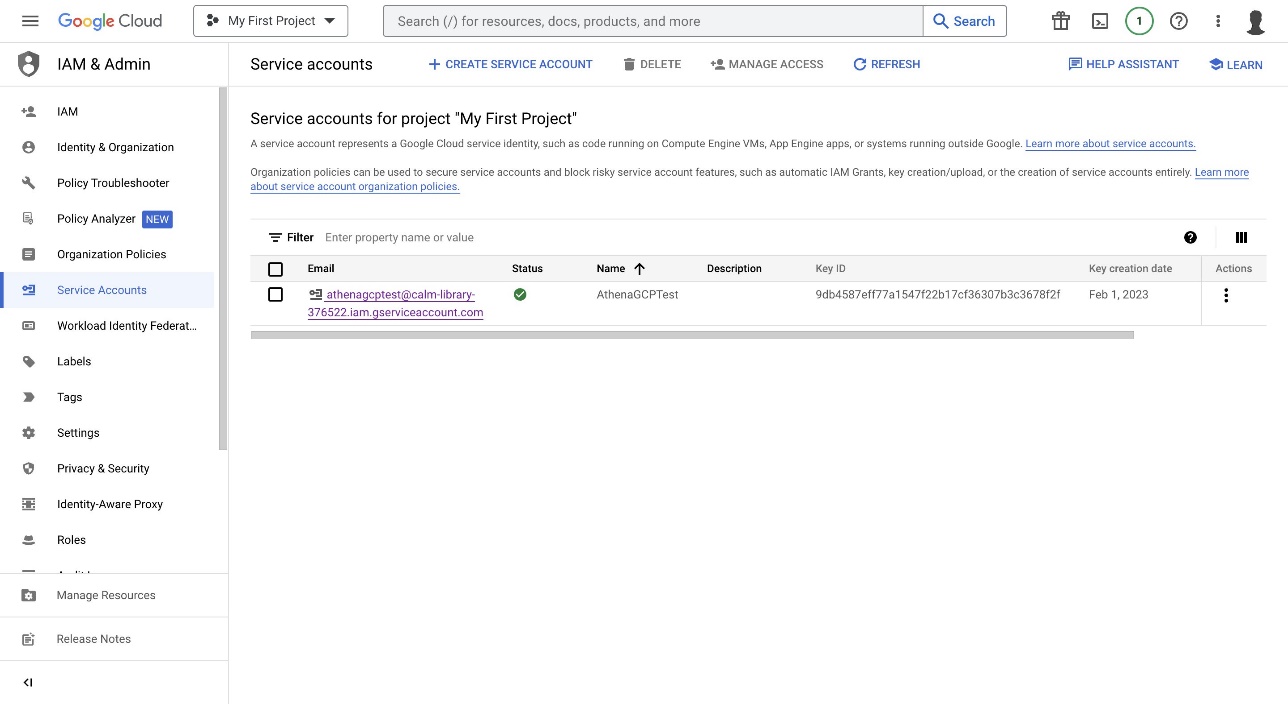
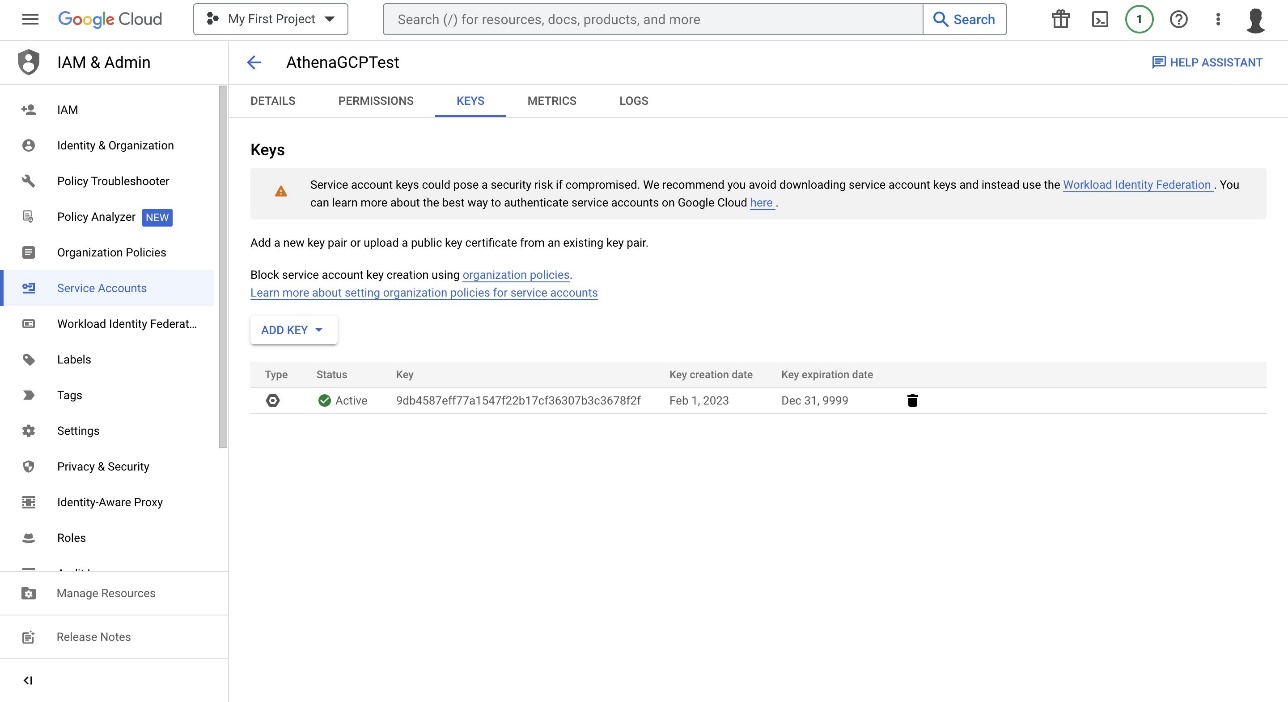
After you create the service account, you can create a key. For instructions, refer to Create and delete service account keys.
AWS configuration
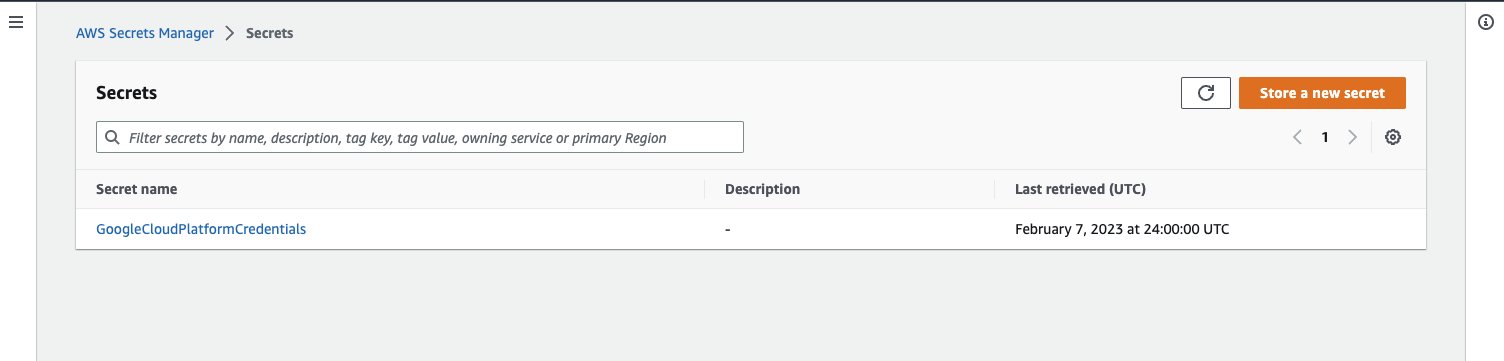
Now that you have a GCS bucket with a CSV file and a generated JSON key file from Google Cloud Platform, you can proceed with the rest of the steps on AWS.
- On the Secrets Manager console, choose Secrets in the navigation pane.
- Choose Store a new secret and specify Other type of secret.
- Provide the GCP generated key file content.
The next step is to deploy the Athena Google Cloud Storage connector. For more information, refer to Using the Athena console.
- On the Athena console, add a new data source.
- Select Google Cloud Storage.
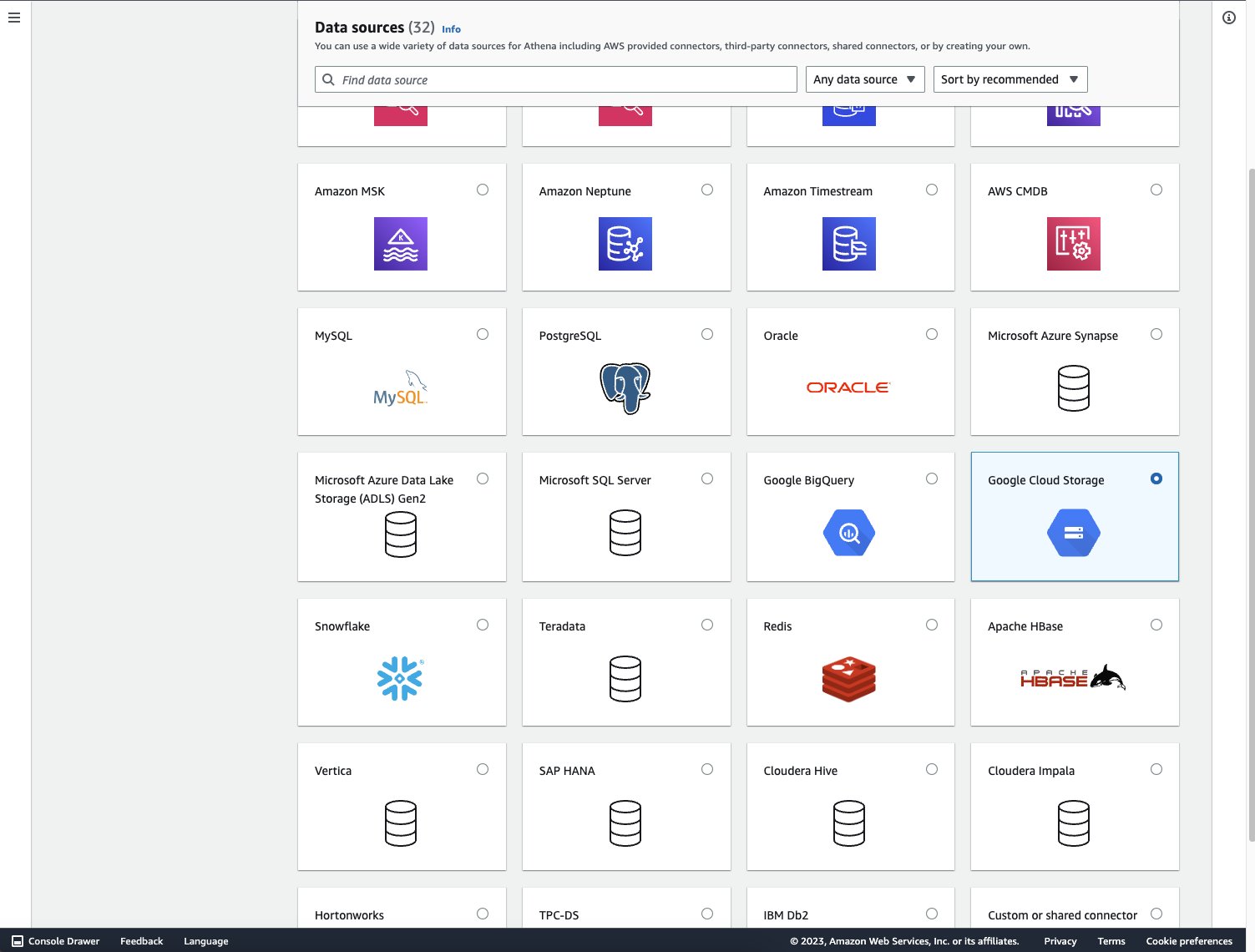
- For Data source name, enter a name.
- For Lambda function, choose Create Lambda function to be redirected to the Lambda console.
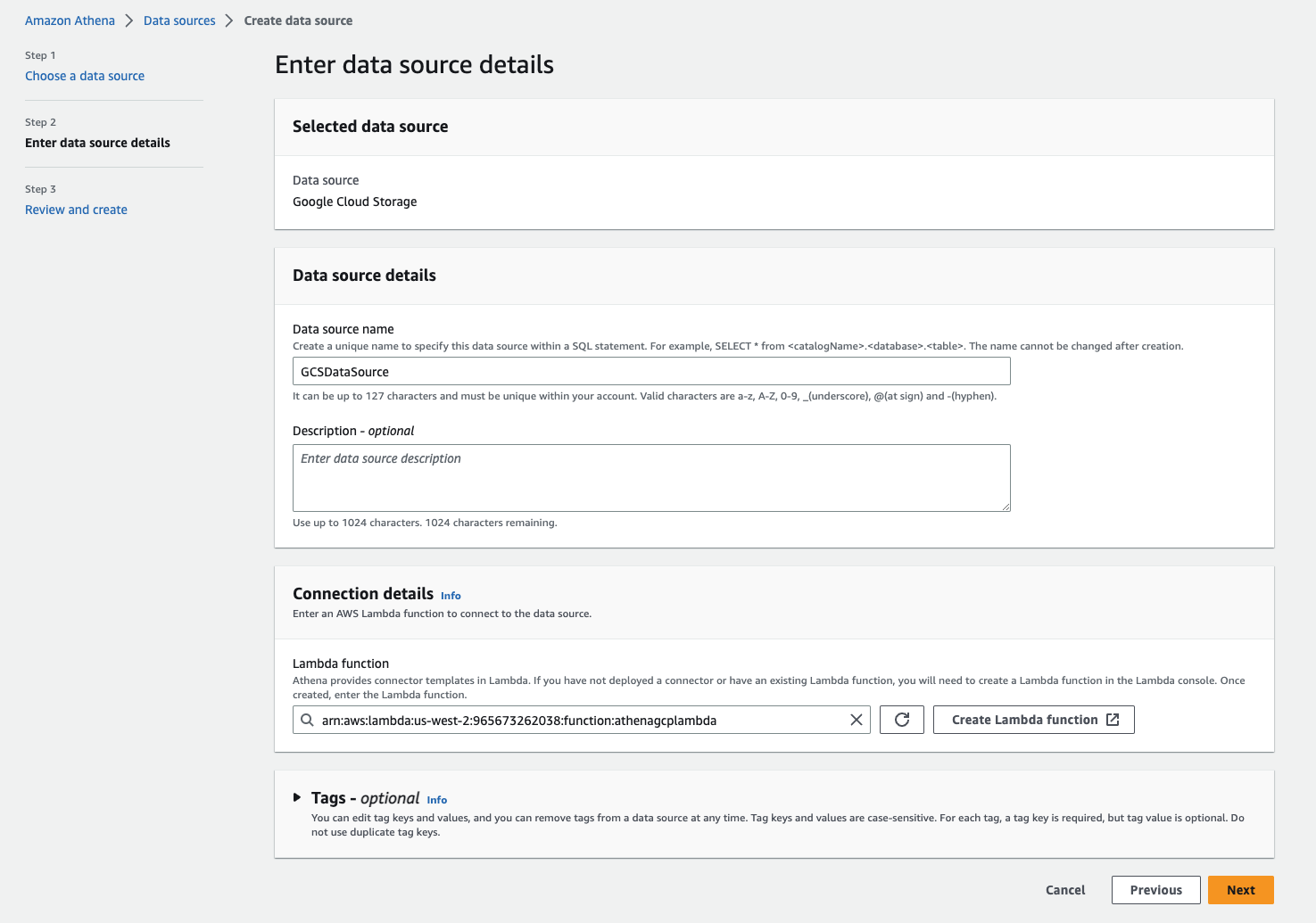
- In the Application settings section, enter the information for Application name, SpillBucket, GCSSecretName, and LambdaFunctionName.
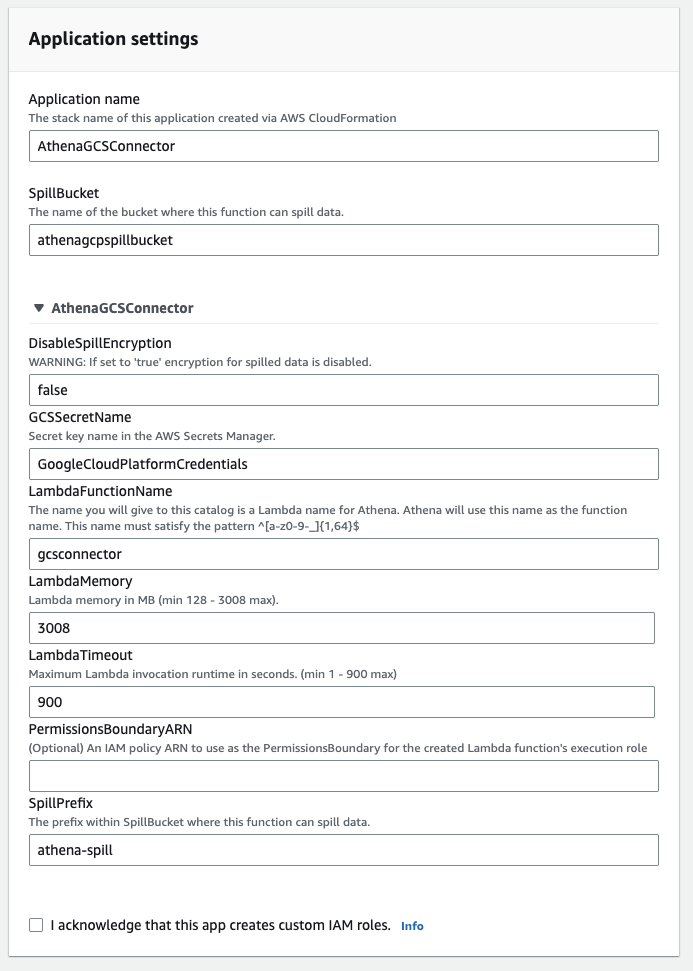
- You also have to create an S3 bucket to reference the S3 spill bucket parameter in order to store data that exceeds the Lambda function’s response size limits. For more information, refer to Create your first S3 bucket.
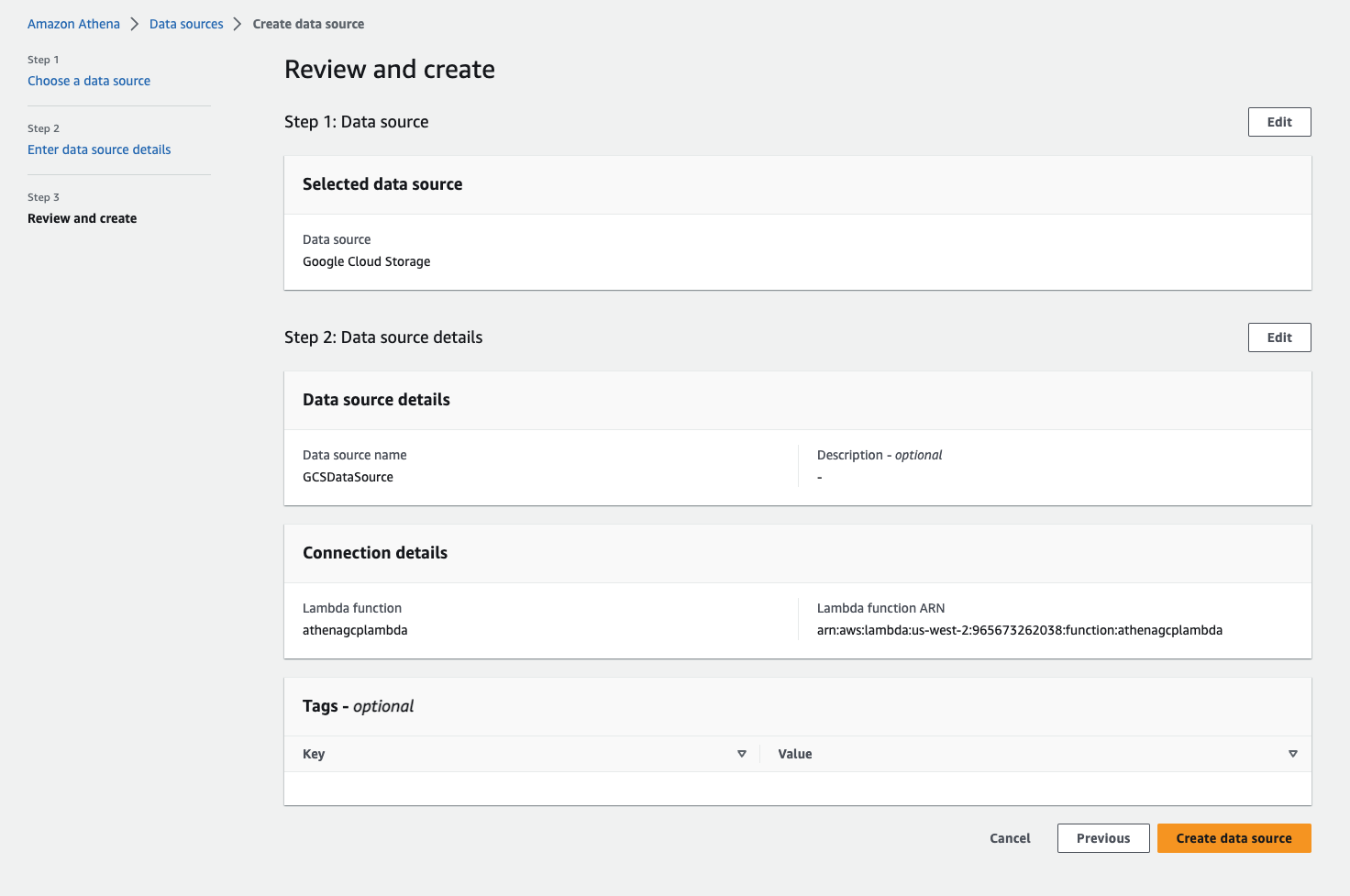
After you provide the Lambda function’s application settings, you’re redirected to the Review and create page.
- Confirm that these are the correct fields and choose Create data source.
Now that the data source connector has been created, you can connect Athena to the data source.
- On the Athena console, navigate to the data source.
- Under Data source details, choose the link for the Lambda function.
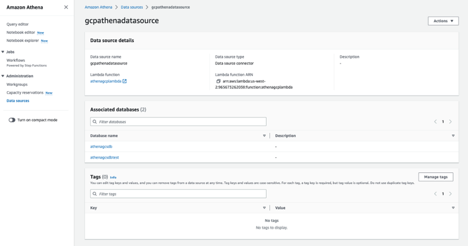
You can reference the Lambda function to connect to the data source. As an optional step and for validation, the variables that were put into the Lambda function can be found within the Lambda function’s environment variables on the Configuration tab.

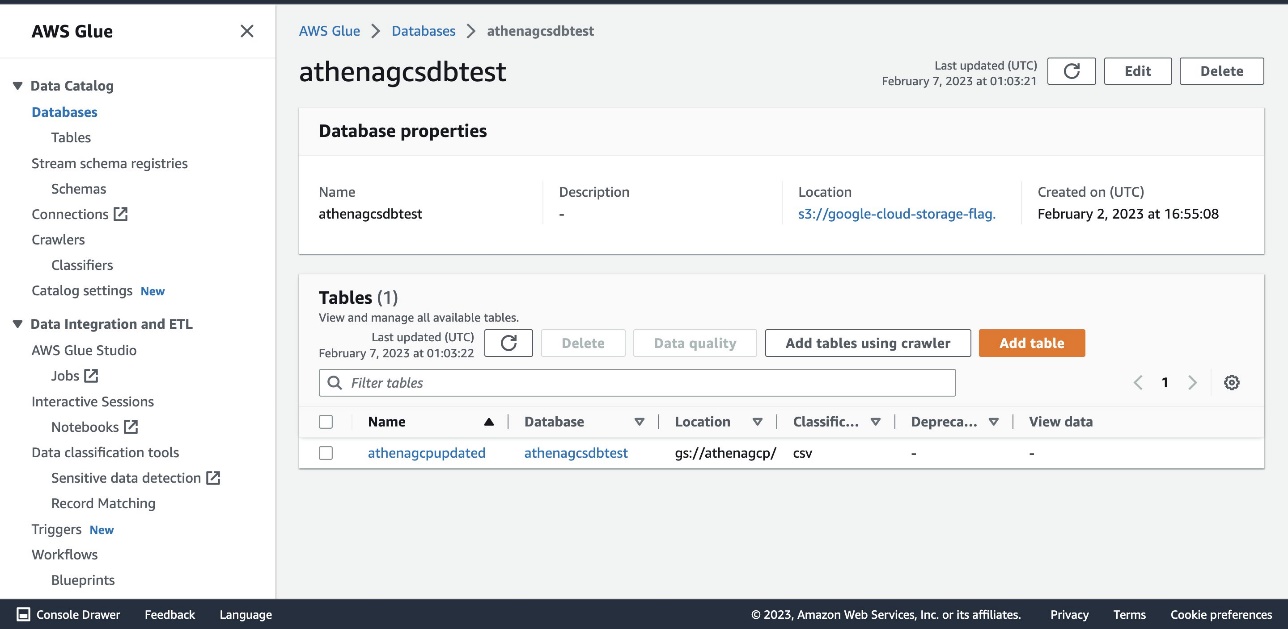
- Because the built-in GCS connector schema inference capability is limited, it’s recommended to create an AWS Glue database and table for your metadata. For instructions, refer to Setting up databases and tables in AWS Glue.
The following screenshot shows our database details.
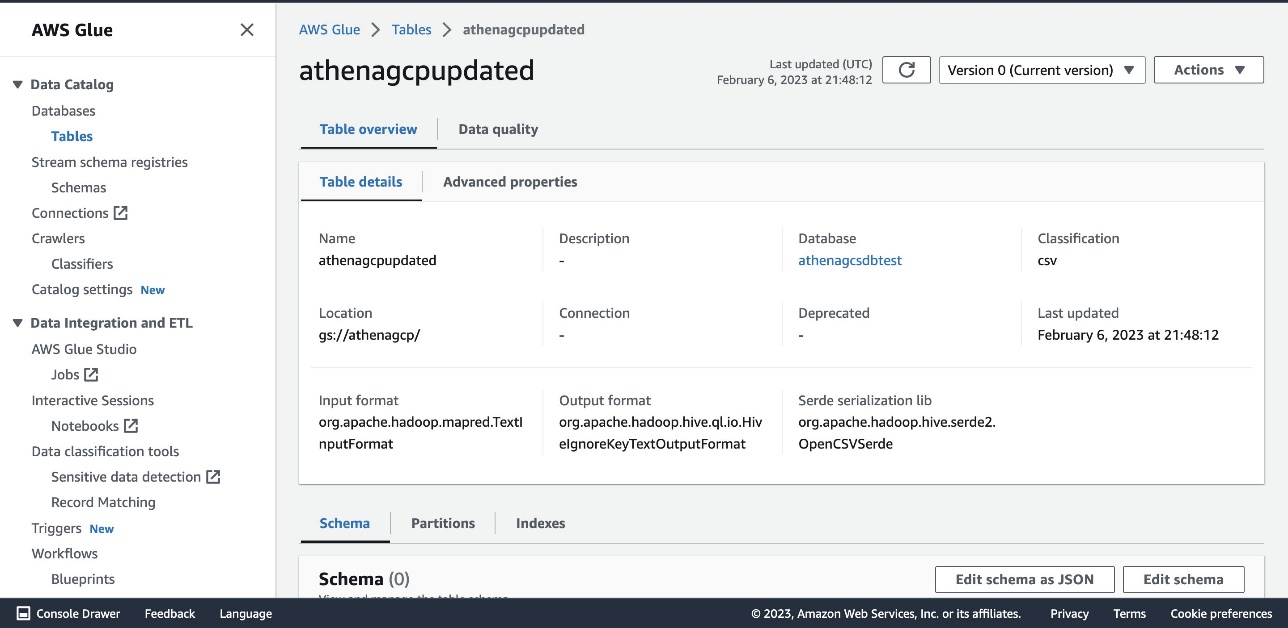
The following screenshot shows our table details.
Query the data
Now you can run queries on Athena that will access the data stored on Google Cloud Storage.
- On the Athena console, choose the correct data source, database, and table within the query editor.
- Run
SELECT * FROM [AWS Glue Database name].[AWS Glue Table name]in the query editor.
As shown in the following screenshot, the results will be from the bucket on Google Cloud Storage.
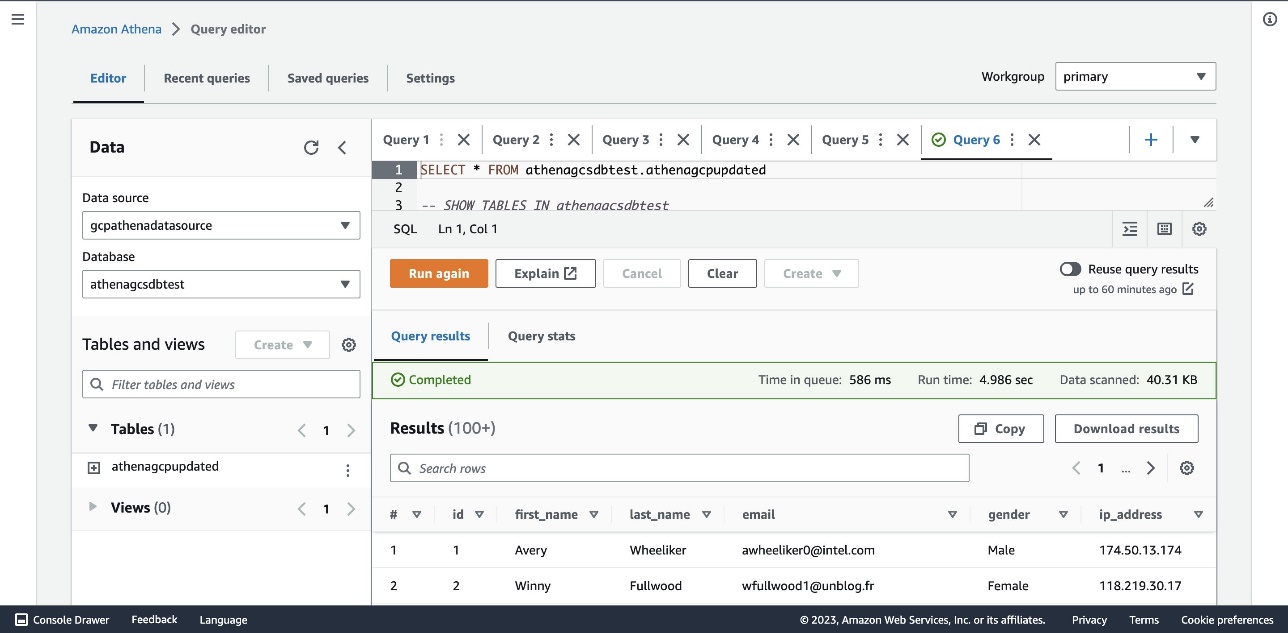
The data that is stored on Google Cloud Platform can be accessed through AWS and used for many use cases, such as performing business intelligence, machine learning, or data science. Doing so can help unblock developers and data scientists so they can efficiently provide results and save time.
Clean up
Complete the following steps to clean up your resources:
- Delete the provisioned bucket in Google Cloud Storage.
- Delete the service account under IAM & Admin.
- Delete the secret GCP credentials in Secrets Manager.
- Delete the S3 spill bucket.
- Delete the Athena connector Lambda function.
- Delete the AWS Glue database and table.
Troubleshooting
If you receive a ROLLBACK_COMPLETE state and “can not be updated error” when creating the data source in Lambda, go to AWS CloudFormation, delete the CloudFormation stack, and try recreating it.
If the AWS Glue table doesn’t appear in the Athena query editor, verify that the data source and database values are correctly selected in the Data pane on the Athena query editor console.
Conclusion
In this post, we saw how you can minimize the time and effort required to access data on Google Cloud Platform and use it efficiently on AWS. Using the data connector helps organizations become multi-cloud agnostic and helps accelerate business growth. Additionally, you can build out BI applications with the discoveries, relationships, and insights found when analyzing the data, which can further your organization’s data analysis process.
About the Author
 Jonathan Wong is a Solutions Architect at AWS assisting with initiatives within Strategic Accounts. He is passionate about solving customer challenges and has been exploring emerging technologies to accelerate innovation.
Jonathan Wong is a Solutions Architect at AWS assisting with initiatives within Strategic Accounts. He is passionate about solving customer challenges and has been exploring emerging technologies to accelerate innovation.