Optimizing Data Analytics: Integrating GitHub Copilot in Databricks
Integrating AI-powered pair programming tools for data analytics in Databricks optimizes and streamlines the development process, freeing up developer time for innovation.
Introduction
GitHub Copilot is an artificial intelligence-powered code completion assistant developed by GitHub and in collaboration with OpenAI, leveraging the ChatGPT model. It's designed to assist developers in accelerating their coding process while minimizing errors. The underlying model is trained on a blend of licensed code from GitHub's own repositories as well as publicly available code, equipping it with a broad understanding of programming paradigms.
On the other hand, Databricks, an open analytics and cloud-based platform founded by the original creators of Apache Spark, empowers organizations to construct data analytics and machine learning pipelines seamlessly, thereby accelerating innovation. Additionally, it fosters collaborative work among users.
Integrating GitHub Copilot with Databricks empowers data analytics and machine learning engineers to deploy solutions efficiently and in a time-effective manner. This integration facilitates smoother code development, enhances code quality and standardization, boosts cross-language efficiency, speeds up prototype development, and aids in documentation, consequently elevating the productivity and efficiency of engineers.
Prerequisites for GitHub Copilot and Databricks Integration:
Databricks account setup.
Setting up GitHub Copilot.
Download and install Visual Studio Code.
Steps for Integration
Install Databricks Plugin in Visual Studio Code Marketplace.
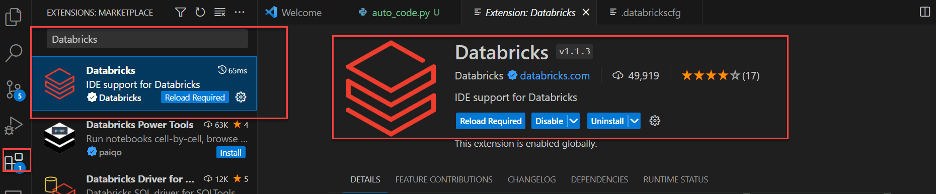
Configure the Databricks Plugin in Visual Studio Code. If you have used Databricks CLI before, then it’s already configured for you locally in databrickscfg file. If not, create the following contents in ~/.databrickscfg file.
[DEFAULT]
host = https://xxx
token = <token>
jobs-api-version = 2.0
Click the “Configure Databricks” option, then choose the first option from the dropdown, which displays the hostname configured in the above step, and continue with the “DEFAULT” profile.
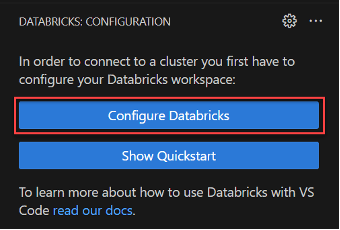
After completing the configuration, a Databricks connection is established with Visual Studio Code. You can see the workspace and cluster configuration details when you click on the Databricks plugin.
Once a user completes the GitHub Copilot account setup, make sure you have access to GitHub Copilot. Install GitHub Copilot and GitHub Copilot Chat Plugins in VSCode via Marketplace.

Once a user installs GitHub Copilot & Copilot Chat plugins, it will be prompted to sign in to GitHub Copilot through Visual Studio IDE. If it’s not prompted to authorize, then click the bell icon in the bottom panel of Visual Studio code IDE.

Now, it’s time development with GitHub Copilot
Developing a Data Engineering Pipeline
Data Engineers can utilize GitHub Copilot to write data engineering pipelines at fingertips at a faster pace, including documentation, within no time. Below are the steps to create a simple data engineering pipeline with prompting techniques.
Read files from the S3 bucket using Python and Spark framework.

Write data frame to S3 bucket using Python and Spark framework

Execute the functions through the main method: Represented same in prompt and resulted from the code with execution steps

Benefits of Using GitHub Copilot for Data Engineering and Machine Learning in Databricks
- Good AI pair programming tool for quick sensible suggestions and provides boilerplate code.
- Top-notch suggestions to optimize the code & run time.
- Better documentation and ASCII representation for logical steps.
- Faster data pipeline implementation with minimal errors.
- Explain existing simple/complex functionality in detail and suggest intelligent code refactoring techniques.
Cheat Sheet
- Opens a Co-pilot text/search bar where you can enter your prompts.

Windows: [Cltr] + [I]Mac: Command + [I]

- Opens a separate window on the right with the top 10 code suggestions.
Windows: [Cltr] + [Enter]
Mac: [control] + [return]

- Open a separate copilot chat window on the left side.
Windows: [Cltr] + [Alt] + [I]
Mac: [Control] + [Command] + [I]
- Dismiss an inline suggestion.
Windows/Mac: Esc
- Accept a suggestion.
Windows/Mac: Tab
- Refer to previous suggestions.
Windows: [Alt] + [
Mac: [option] + [
- Check for next suggestion
Windows: [Alt] + ]
Mac: [option] + ]
Conclusion
Integration of AI pair programming tools with integrated development environments helps developers speed up the development with real-time code suggestions, reducing time spent on referring to documentation for boilerplate code and syntaxes, and enabling developers to focus on innovations and business problem-solving use cases.
Further Resources
- https://app.pluralsight.com/library/courses/getting-started-prompt-engineering-generative-ai/table-of-contents
- https://docs.github.com/en/copilot/quickstart
Naresh Vurukonda is a Principal Architect with 10 plus years of experience in building Data Engineering and Machine learning projects in Healthcare and Life Sciences and Media Network organizations.