
Is Direct Lake semantic model storage mode the silver bullet?
I just returned from the Microsoft Fabric Community Conference in Las Vegas. Over 4,000 attendees saw a lot of demos showing how to effortlessly build a modern data platform with petabytes of data in One Lake, and then ask CoPilot to generate beautiful Power BI reports from semantic models that magically appear from data in a Fabric Lakehouse. Is Direct Lake the silver bullet solution that will finally deliver incredibly fast analytic reporting over huge volumes of data in any form, in real time? Will Direct Lake models replace Import model and solve the dreaded DirectQuery mode performance problems of the past? The answer is No, but Direct Lake does break some barriers and exceed previous limitations, and it introduces a different approach to architect enterprise-scale analytic solutions. This post is a continuation of my previous post titled “Moving from Power BI to Microsoft fabric“.
Direct Lake is a new semantic model storage mode introduced in Microsoft Fabric, available to enterprise customers using Power BI Premium and Fabric capacities. It is an extension of the Analysis Services Vertipaq in-memory analytic engine that reads data directly from the Delta-parquet structured storage files in a Fabric lakehouse or warehouse.
How Direct Lake differs from Import mode
Since the introduction of Power Pivot for Excel, SQL Server Analysis Services Tabular, Azure Analysis Services and Power BI; the native mode for storing data for an in-memory “tabular” semantic data model (previously called a “dataset” in Power BI) has been a proprietary file structure consisting of binary and XML files. These file structures were established in the early days of multidimensional SSAS back in 2000 and 2005. When an Import mode model is published to the Power BI service, deployed to an SSAS server or when Power BI Desktop is running, data for the model is loaded into memory where it remains as long as the service is running. When users interact with a report or when DAX queries are run against the model, results are retrieved very quickly from the data residing in memory. There are some exceptions for very large models or when many models in the service don’t all fit into memory at the same time, the service will page some or all of the model in and out of memory to make sure that the most-often used model pages remain in memory for the next user request. But, for argument’s sake, the entire semantic model sits in memory, waiting for the next report or user request. The only way to get new or updated data into the model was to refresh or process all or part of the model, replacing the on-disk storage files with new data form the data source – which, in turn, updates the in-memory data available to reports. This typically meant that the information shown in analytic reports was a few hours or days old – depending on the frequency of ETL processes and scheduled refresh cycles.
Rather than the proprietary SSAS file structure, Direct Lake models use the native Delta-parquet files that store structured data tables for a Fabric lakehouse or warehouse in One Lake. And rather than making a copy of the data in memory, the semantic model is a metadata structure that shares the same Delta-parquet file storage. As soon as a report is viewed, all of the semantic model data is paged into memory which then behaves a lot like an Import mode model. This means than while the model remains in memory, performance should about the same as Import, with a few exceptions.
Since Direct Lake models can be considerably larger than typical Import models, they are likely to have some data paged in and out of memory to make room for competing processes in the same capacity. The service also tracks changes in the underlying Delta files and must swap the corresponding semantic model pages so that the model remains in-synch. After some idle time, depending on other processing demands, the entire model may be paged out of memory. When the model is used again, perhaps hours or days later, the data must be paged back into memory for the next user request.
All of this means that once the semantic model data is loaded into memory, it can provide very fast access to results and report interactions over a much larger volume of data than ever before. Additionally, when records are inserted, updated or deleted in the underlying lakehouse or warehouse behind the semantic model, those changes are available in the report within a matter of seconds.
Default semantic models and explicitly-created semantic models
Every lakehouse or warehouse in Fabric has a corresponding semantic model. Since a Direct Lake model itself requires no memory unless it is used for reporting, default models are very lightweight and require no resources aside for a tiny bit of storage. These default models are a semantic representation of the underlying database and don’t contain relationships, measures or any other enhancements unless they are explicitly added by a developer.
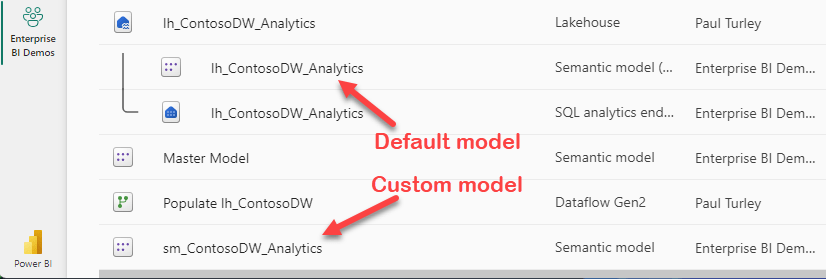
When you explicitly create a new semantic model from a lakehouse or warehouse, you choose the tables to include and then design relationships, measures, hierarchies, display folders and other modeling objects just as you would in Power BI Desktop.
Having more bullets means users have more opportunities to shoot themselves in the foot
Call me a Nay-Sayer but I’m not a big fan of all these new models just showing up and I would not encourage users just to go willy nilly building reports from them. In fact, I think we’re in for a flood of new problems caused by business users relying on data models that have not been carefully crafted and curated. After all, data modeling is at the core of analytic reporting and years of industry experience has shown that incorrectly modelled data will provide bad results. My initial advice is to lock them down and then build models to support specific reporting scenarios.
DirectQuery fallback
Fallback occurs when a table in the semantic doesn’t support Direct Lake mode or when the semantic model query engine reaches a resource limit. These are well-defined “guardrails” that vary by capacity size, model size and environment. You can read more technical details in the Direct Lake overview article on Microsoft Learn but I’ll cover the basics here. Direct Lake fallback is affected by:
- Overall data volume of the semantic model in storage
- Amount of memory a specific DAX query uses
- Table row count
- Number of parquet files needed to store each table used in the query
For Direct Lake mode to work effectively, it can only read from a fixed number of Delta parquet files at a time (numbered in the thousands). To understand this in-depth, we’d have to get into the guts of Spark and Delta storage but the limitation is based on the maximum number of files or row group files per table. For example, an F32 capacity allows Direct Lake mode queries when there are up to one thousand files or row groups per table and F64/P1 supports up to five thousand files. There are also stated limits based on the amount of memory a query would use, which is typically proportional to the size of the model. An F64 or P1 capacity supports DAX queries that use up to 25 GB of RAM in the service, and will fallback to DirectQuery if the limit is exceeded.
There are a couple of ways to see of a query falls back to DirectQuery. The most obvious is that performance will suddenly deteriorate significantly. DirectQuery over a lakehouse or warehouse converts DAX to T-SQL using the SQL endpoint and these queries take longer to run. Secondly, use the Performance Analyzer in Power BI Desktop to view the query for a given page visual. If it shows a SQL query step in the execution, then you are in fallback mode.
Design considerations
Enterprise-class analytic solutions using Direct Lake mode semantic models are built on the premise that data transformations and preparation take place before Power BI. This is important to understand because certain best-practices and design patterns are the same in principle but different in application.

For example: incremental refresh and incremental updates, table partitioning, query folding, calculated columns and friendly object naming are all important considerations for an enterprise semantic model but are applied differently with Direct Lake models. These are not limitations or feature gaps per-se but characteristics of a mature analytic platform. Let’s break these down and point out the differences, compared to the way we do things in conventional Power BI solutions.
Incremental refresh and updates
Fabric solutions will absolutely support incremental refresh but it is not applied to semantic model tables like it is in Power BI Desktop. Incremental refresh is a feature (soon to be in Preview as I write this) in Gen2 Dataflows. This was announced at the Microsoft Fabric Community Conference last week (March 2024). It will work much the same way this it does in Power BI, but it is applied at the M query level, in the ETL layer of the solution between the data source and destination lakehouse or warehouse.
Partitioned tables
Guess what? Fabric lakehouses and warehouses already have table partitioning built-in. It’s a core part of the Delta parquet storage for lakehouses. In fact, there is much more to it than partitioning. A Delta table is a collection of parquet files that are usually partitioned and order and optimized specifically to meet certain requirements. Extensive documentation about maintaining and optimizing lakehouse and Delta storage can be found in Microsoft Learn here: Lakehouse and Delta tables – Microsoft Fabric | Microsoft Learn
Query folding
Assuming that you are using Dataflows gen2 for data transformations, the tenants of query optimization are the same as Power Query in Power BI Desktop. If data sources for the dataflow queries relational, the same best practices generally apply: use tables or views rather than in-line SQL statements and avoid transformations that break query folding. If you need to perform expensive, resource-intensive transformations, push them upstream as far as possible. Gen2 dataflows also offer new optimization options to speed things up, like lakehouse staging. Additional optimizations are planned in the near future that will make Power Query perform much faster with the Spark engine and Delta storage, and allow more queries to be executed in parallel.
Calculated columns
There is a good reason that DAX-based calculated columns aren’t supported in Direct Lake semantic models and that is that the model relies on data being stored directly in the lakehouse or warehouse tables, and columns must match one-for-one to the model. If you need a calculated or aliased column, created in the data transformation layer that populates the lakehouse or warehhouse. Performing transformations and row-level calculations upstream has always been a recommended best practice. In a fabric solution using Direct Lake, it is simply enforced by design.
Using tables or views in source tables
Don’t use views as table sources in a Direct Lake model …you can’t. Once again, it is not a feature gap… it is by design. At first, it took me a while to get use to this perceived “limitation” because I’ve always promoted using views to make sure query folding works in Power Query. However, with Power Query moved into the transformation layer, before the lakehouse or warehouse in the fabric enterprise architecture; using views is no longer an enterprise design pattern in the lakehouse or warehouse feeding the semantic model. This is because Direct Lake relies on data being stored directly in the lakehouse or warehouse tables. Direct Lake simply can’t work when you use views instead of tables.
Friendly object naming
This change also took me some time to adjust my view. I’m very adamant about making sure that every visible object in a semantic model uses friendly names. Every table, column and measure in a model should use mixed-case names with spaces – period… no exceptions. No scary names. It freaks users out.
In the past, we have often renamed columns in database views or in the Power Query queries, but we can no longer use that approach because the Spark engine behind Fabric lakehouses and warehouses doesn’t support column names containing spaces. It’s a fact… just accept it and rename all the tables and columns in the semantic model designer. and the same rules apply as before… no implicit measures. Hide all the numeric columns in your fact tables, along with the primary and foreign keys, and any other columns that we don’t want users to see; and create explicit measures with easy-to-read, friendly names.


Paul, the link to the previous post in the introduction appears to be broken.