Baize: An Open-Source Chat Model (But Different?)
So what's new in the LLM space? Meet Baize, an open-source chat model that leverages the conversational capabilities of ChatGPT. Learn how Baize works, its advantages, limitations, and more.

Image by Author
I think it’s safe to say 2023 is the year of Large Language Models (LLMs). From the widespread adoption of ChatGPT, which is built on the GPT-3 family of LLMs, to the release of GPT-4 with enhanced reasoning capabilities, it has been a year of milestones in generative AI. And we wake up everyday to the release of new applications in the NLP space that leverage the ChatGPT’s capabilities to address novel problems.
In this article, we’ll learn about Baize, a recently released open-source chat model.
What is Baize?
Baize is an open-source chat model. Cool. But why another chat model?
Well, in a typical session with a chatbot, you don't have a single question that you’re seeking an answer to. Rather, you’ll ask a series of questions that the bot answers. This conversation chain continues—until you get your answers or an acceptable solution to your problem—in this multi-turn chat.
So if you want to start building your own chat models, such a multi-turn chat corpus is not super common to come by. Baize aims at facilitating the generation of such a corpus using ChatGPT and uses it to fine-tune a LLaMA model. This helps you build better chatbots with reduced training time.
Project Baize is funded by the McAuley lab at UC San Diego, and is the result of collaboration between researchers at UC San Diego, Sun Yat-Sen university, and Microsoft Research, Asia.
Baize is named after the Chinese mythical creature Baize that can understand human languages [1]. And understanding human languages is something we’d all like chat models to have, yes? The research paper for Baize was first uploaded to arxiv on 3rd April, 2023. The model’s weights and code have all been made available on GitHub solely for research purposes. So now is a great time to explore this new open-source chat model.
And, yeah, let's learn more about Baize.
How Does Baize Work?
The working of Baize can be (almost) summed up in two key points:
- Generate a large corpus of multi-turn chat data by leveraging ChatGPT
- Use the generated corpus to fine-tune LLaMA
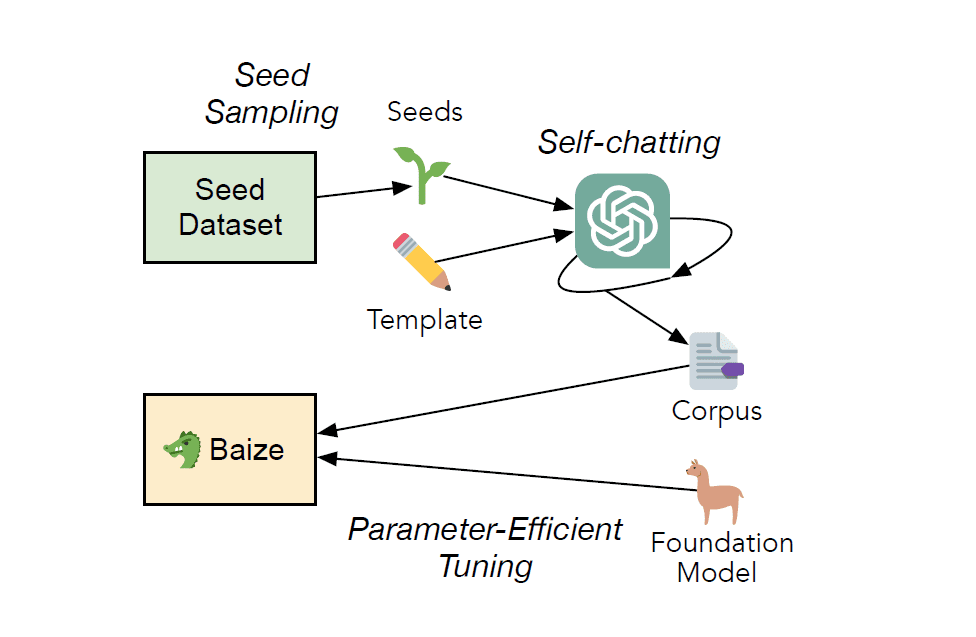
The Pipeline for Training Baize | Image source
Data Collection with ChatGPT Self-Chatting
We mentioned that Baize uses ChatGPT to construct the chat corpus. It does so using a process called self-chatting in which ChatGPT has a conversation with itself.
A typical chat session requires a human and an AI. The self-chatting process in the data collection pipeline is designed such that ChatGPT has a conversation with itself—to supply both sides of the conversation. For the self-chatting process, a template is provided along with the requirements.
The quality of conversations generated by ChatGPT is quite high (we’ve seen this more in our social media feeds than in our own ChatGPT sessions). So we get a high-quality dialogue corpus.
Let's take a look at the data used by Baize:
- There is a seed that sets the topic for the chat session. It can be a question or a phrase that supplies the central idea of the conversation. In the training of Baize, questions from StackOverflow and Quora were used as seeds.
- In the training of Baize, ChatGPT (gpt-turbo-3.5) model is used in the self-chatting data collection pipeline. The generated corpus has about 115K dialogues—with approximately 55K dialogues coming from each of the above sources.
- In addition, data from Stanford Alpaca was also used.
- Currently three versions of the model: Baize-7B, Baize-13B, and Baize-30B have been released. (In Baize-XB, XB denotes X billion parameters.)
- The seed can also be sampled from a specific domain. Meaning we can run the data collection process to construct a domain-specific chat corpus. In this direction, the Baize-Healthcare model is available, trained on the publicly available MedQuAD dataset to create a corpus of about 47K dialogues.
Fine-Tuning in Low-Resource Settings
The next part is the fine-tuning of the LLaMA model on the generated corpus. Model Fine-tuning is generally a resource-intensive task. As tuning all the parameters of a large language model is infeasible under resource constraints, Baize uses Low-Rank Adaptation (LoRA) to fine tune the LLaMA model.
In addition, at inference time, there’s a prompt that instructs Baize not to indulge in conversations that are unethical and sensitive. This mitigates the need for human intervention in moderation.
The functional app fetches the LLaMA model and LoRA weights from the HugingFace hub.
Advantages and Limitations of Baize
Next, let’s go over some of the advantages and limitations of Baize.
Advantages
Let’s start by stating some advantages of Baize:
- High availability: You can try out Baize-7B on HuggingFaces spaces or run it locally. Baize is not restricted by the number of API calls and alleviates concerns of availability in times of high demand.
- Built-in moderation support: The prompts at inference time to stop indulging in conversations on sensitive and unethical topics is advantageous as it minimizes efforts needed to moderate conversations.
- Chat corpora generation: As mentioned, Baize can help build large corpora of multi-turn conversations. This can be helpful in training chat models at scale.
- Accessibility in low-resource settings: As mentioned in [1], we can run Baize on a single GPU machine, which makes it accessible in low-resource settings that have limited access to computation resources.
- Domain-specific applications: By carefully sampling the seed from a specific domain, we can have chat bots for domain-specific applications such as healthcare, agriculture, finance and more.
- Reproducibility and customization: The code is publicly available and the data collection and training pipeline is reproducible. If you want to collect data from various specific sources to build a custom corpus, you can modify the <code>collection.py</code> script in the project’s codebase.
Limitations
Like all LLM-powered chat apps, Baize has the following limitations:
- Inaccurate information: Just the way ChatGPT’s responses are sometimes prone to inaccuracies resulting from outdated training data and contextual nuances, Baize’s responses might as well be technically inaccurate at times.
- Challenge with up-to-date information: The LLaMA model is not trained on recent data. This makes it challenging for tasks that require up-to-date information for accurate and helpful response.
- Bias and toxicity: By changing the inference prompt, the behavior of the model to decline engaging in sensitive, unethical conversations can be manipulated.
Wrapping Up
That’s all for today! To explore more about Baize, be sure to try out the demo on HuggingFace spaces or run it locally. ChatGPT and GPT-4 have inspired a wide range of applications in the NLP space.
With novel OpenAI wrappers hitting the developer space almost everyday, it can be overwhelming to keep up with these rapid advancements and releases. At the same time, we’re excited to see what the future of generative AI holds.
References and Resources for Further Learning
[1] C Xu, D Guo, N Duan, J McAuley, Baize: An Open-Source Model with Parameter-Efficient Tuning on Self-Chat Data, arXiv, 2023.
[3] Demo on HuggingFace Spaces
Bala Priya C is a technical writer who enjoys creating long-form content. Her areas of interest include math, programming, and data science. She shares her learning with the developer community by authoring tutorials, how-to guides, and more.