





This is a blog post from our friends at Aimpoint Digital. Aimpoint Digital is a leading advanced analytics, data science, and engineering services firm that operates as the trusted advisor for companies looking to extract tangible value from data.
The emergence of Large Language Models (LLMs) like OpenAI's ChatGPT series has paved the way for countless new opportunities in the field of data analytics. These powerful models enable individuals without coding expertise to easily access, comprehend, and analyze complex datasets. By simply asking them to visualize, condense, interpret, and then extract insights from a dataset, data analytics capabilities are becoming more inclusive and available to a broader audience.

Unfortunately, these models are incredibly complex — they contain thousands of lines of code, millions of training data points, and billions of trained model parameters. It can be intimidating to pick them up, tune them to your particular use case, and begin to harness their true value efficiently.
The good news is that you can integrate these LLMs with Dataiku to harness the capabilities of large language models in an enterprise setting.
In this blog, we discuss additional ways conversational ChatGPT prompts can enable users to analyze data. Whether you’re an existing Dataiku user looking to use these models in your flow or a data persona looking for ways to add tools like ChatGPT to your organization’s arsenal to quickly realize value, this blog will highlight the power of both Dataiku and generative AI.
Real-Life ChatGPT Use Cases
We have created use cases that allow the creation of visualizations, plots, and summary tables based on simple conversational prompts given by the user. The outputs are highly precise and tailored to your data, delivering an all-inclusive and efficient approach to data analysis and representation. We shall now discuss some of these use cases in detail.
Using ChatGPT to Python Code from Conversational Prompts
Generating accurate SQL queries and Python code can be a daunting task, especially for people with minimum to no coding experience. ChatGPT can generate SQL queries and Python code from plain English prompts that can be readily executed on your datasets.
In our case, we used ChatGPT on an e-commerce transactions dataset to generate insights. The data consists of sales information from different merchants (Walmart, Costco, etc.) over time.
For the purpose of our use case, we wanted to generate Python code specific to the data and execute it to get results. We extract insights pertaining to the sales figures of different merchants that tell us how the different merchants are performing. The charts extracted from this analysis help us dive deeper into some of those trends and patterns specific to each merchant.
To be able to generate code specific to our data, we need to provide the schema of the data as part of our text query to the model. In Figure 1 we can see how to store the schema of the input data in the variable “schema.”
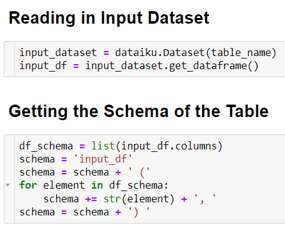
Figure 1. Code to gather the schema of the dataframe ‘input_df’. The schema enables ChatGPT to provide code that is executable on our datasets.
We then let the user enter their prompt. The prompt must contain the dataset name, schema, and the language in which they want the code generated. In our example, we want to get all the transactions that happened at Costco, which you can see in Figure 2.

Figure 2. User prompt along with the name, schema of the associated dataset.
User prompts often need to be reformatted to make them ChatGPT friendly. This makes the response more useful and easily executable. The prompt is “padded” with the dataset name, schema of the dataset, and output language, as shown in the figure below (Figure 3). This step is optional but highly recommended.
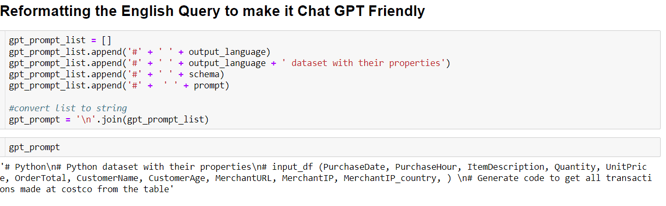
Figure 3. Padding the user prompt with additional information.
There are different models you may pick to use within ChatGPT, but in our case we went with the “text-davinci-003” model – a powerful model adept at language generation. We pass the ChatGPT-friendly prompt generated in the previous step to this model and also set up some parameters (Figure 4).
The temperature ranges from 0 being the least creative (most deterministic) to 1 being the most creative (most probabilistic). The max_tokens parameter is used to provide a limit on the length of the text. This is something that might have to be changed based on how long the code is for a certain operation.
The top_p parameter is another way to control the creativity/diversity of the model (Open AI recommends using either temperature or top_p, but we chose to experiment with both). The penalties help control the repetitions in the prompt being generated. By default, they are set to 0.
It is important to note that you may have to experiment with these settings to get the model to work as you expect. The values we used worked well for our prompts but may not work identically with your prompts.
After defining these parameters, we can call the API and generate the code for the data.
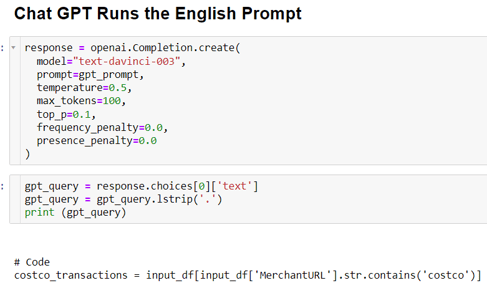
Figure 4. Defining parameters for the text-davinci-003 model. Notice the code generated at the bottom.
Once the code is generated, we can execute it and look at the results as shown in Figure 5.
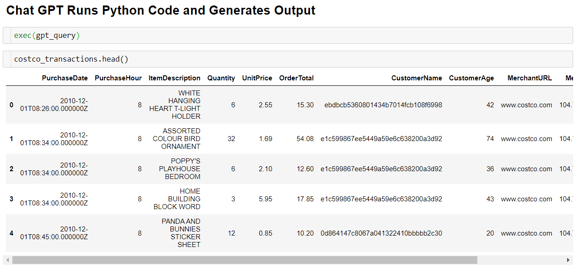
Figure 5. Code generated by the model has been executed on our ecommerce data.
Using ChatGPT to Explain Code to Non-Technical Users
The code generated by ChatGPT is usually well documented and easy to follow. Yet explaining production-level Python code to non-technical members can be a challenging task.
ChatGPT can explain line by line what the Python code is doing. This tool can democratize code by allowing non-coders to understand code in plain English. This is an extremely helpful feature for all the non-technical users to get a better understanding of the code generated and then execute it to make sure the results are accurate. We can see that in the example shown in Figure 6 below.

Figure 6: Code generated by model with comments.
Generating Visuals using ChatGPT
ChatGPT cannot directly generate visuals, but it can generate code that may be later used to quickly generate plots, charts, etc. The code may be generated directly from text prompts and can be very useful to quickly generate visuals for a presentation.
Just like other examples of LLMs in the data realm, the quality of the response greatly depends on the specificity of the prompt. Furthermore, padding your prompt with details such as the language you want the output code in, the name of the dataset, and the dataset schema will help ChatGPT generate code that is specific to your data and use case.
In the following use case, we input a text prompt to generate a pie chart from the e-commerce transactions dataset.
Initial Prompt
Generate code to plot and save a pie chart showing the total quantity of goods sold at all the different merchants.
While ChatGPT can generate code based on the above output, it is likely going to be generic and not directly applicable to our specific dataset. To tailor our request, we pad the original prompt to include some additional information (coding language, dataset name, column names, etc.).
Modified Prompt
Python dataset with their properties input_df (PurchaseDate, PurchaseHour, ItemDescription, Quantity, UnitPrice, OrderTotal, CustomerName, CustomerAge, MerchantURL, MerchantIP, MerchantIP_country, )
Read in a dataset called input_df.csv.
Generate code to plot and save a pie chart showing the total quantity of goods sold at all the different merchants.
The modified prompt is more detailed and is therefore superior to the initial prompt. ChatGPT generated the following code based on the modified prompt.

Figure 7: Code generated by ChatGPT to build a pie chart based on the ecommerce data.
This code is readily executable (Figure 7) and the resulting pie chart (Figure 8) from running this code is shown below. While the model managed to generate perfectly accurate code in this example, there may be times when the resulting code may require some tweaking. The quality of the prompt will determine the amount of code modifications required before it can be run error-free to generate the output you desire.
Figure 8: Pie chart plotted using the code generated by the model
Limitations of LLMs in the Context of Data
ChatGPT is truly a remarkable achievement for all of humankind in our quest to achieve Artificial General Intelligence (AGI). While we’re not there yet, the workings of the model have awed almost everybody, and its successors are only going to get better.
Following the public release of ChatGPT via OpenAI’s API people around the world are developing applications and plugins using its capabilities that are going to be used across the planet. As such, it is imperative for us to understand the limitations of LLMs and how we must use them responsibly.
LLMs Can Make Mistakes
ChatGPT has been meticulously trained on astronomical amounts of textual data. The training methodology uses a combination of supervised learning methods, reinforcement learning methods, and human inputs that make these models’ responses human-like and relatable. A lot of effort also goes into making sure the models are up to date with the latest information.
Despite these massive efforts, it is impossible to train models with all the data in the universe. For this simple reason, ChatGPT can make mistakes from time to time, and it is up to us humans to detect when these mistakes are being made. This is particularly important to keep in mind when using LLMs to generate code. The code generated by these models can sometimes be generic and may not directly translate to the datasets you’d like to use them on. Modifying the code to suit your application, and also thoroughly reviewing the code in process for bugs is essential to realizing value.
LLMs Do Not Truly Understand Data
While we have highlighted many applications of ChatGPT in Dataiku, it is important to understand that it does not truly understand the data as we humans do. Let’s consider an example to understand this limitation better.
We have a dataset containing US census data and we are interested in finding the average per-capita income for Cook County in the state of Illinois. ChatGPT may be able to provide you with a response to this prompt if it was exposed to relevant training data during training. However, it is not capable of automatically going into a dataset, identifying the appropriate column, applying necessary filters, and providing you with output. You may prompt ChatGPT to generate code to calculate average per-capita income for Cook County, but it will likely be a generic code that is not directly applicable to your dataset.
As evident, ChatGPT only uses your text input to generate code/responses and is not able to understand data as we humans do. Framing your queries to be more explicit can overcome this limitation to an extent, but it is nevertheless imperative to exercise caution when using responses from ChatGPT — especially when they pertain to data analysis.
Conclusion
In summary, large language models such as ChatGPT are transforming the data analytics domain by making it more inclusive and efficient for users with different coding abilities. Combining ChatGPT with Dataiku creates a potent partnership that enables natural language processing, code production, and code clarification, all while broadening the understanding of data analytics for a wider audience.
Through well-crafted prompts, ChatGPT can generate precise SQL queries, Python code, and even produce visuals for improved data comprehension. Nevertheless, it's crucial to recognize ChatGPT's limitations, including its lack of true data understanding and the occasional creation of incorrect or non-applicable code. By being aware of these limitations and perfecting the skill of posing questions to ChatGPT, users can unleash the models’ full potential and revolutionize their data analytics approaches.
As the advancement of large language models such as ChatGPT continues, the possibilities for development and innovation in the data analytics sphere are boundless. By adopting these powerful tools and integrating them with platforms such as Dataiku, organizations can enable their teams to make informed decisions based on data, regardless of their technical expertise.