





It goes without saying that when it comes to scaling AI, tooling, technology, and being able to go smoothly and efficiently from development or test into the real business are critical pieces, which is why IT teams play an integral role. Yet according to a Dataiku survey of 200 IT professionals, their biggest concern remains — naturally — security.
Finding the right balance between governance and democratization, security and speed, is critical for the success of AI initiatives. This article will identify some of the top challenges IT managers must address to scale AI (and stay tuned for our next article on the most impactful steps they can take to spur organizational transformation).
Finding the Right Balance Between Auditability and Permission Management
Let’s be honest: the easiest way to ensure reliability and security is to make minimal changes, to err on the side of restricting rather than granting access, and to be vigilant about the adoption of new tools (especially those that promote increased access to data). In other words, the very idea of scaling AI through data democratization goes against many traditional security principles, so it’s natural that IT teams are cautious.
However, too much caution can result in the rise of shadow IT (i.e., business units developing applications, infrastructure, or processes that circumvent central IT organizations), which is a particular risk when the business wants to move fast on scaling AI efforts. It is therefore important to be a part of the conversation, taking a step back when it comes to security to determine what makes sense in the context of democratization and how IT teams can both retain an appropriate amount of control while also giving the business the freedom to work with the data they need to optimize decision making.
When it comes to democratizing AI initiatives, security has two components: auditability and permission management, and they can be viewed as two ends of the spectrum with a sliding scale in the middle. Organizations that rely entirely on auditability give unrestricted access and then depend on those audit capabilities to ensure security. On the other end, organizations that rely entirely on permission management tightly control who has access to what at the source.
It’s important to recognize that auditability is a matter of setup — it’s a fixed cost when building a system. On the other hand, permissions have both a fixed cost and an ongoing cost of constant management, which requires lots of internal processes and tooling. When it comes to scaling AI, finding the appropriate balance between the two is the challenge for IT teams and their managers.
Many positions along the auditability/permission management axis make sense, but it depends on what the business is, what kind of data it has (e.g., website data is less sensitive than financial data, and jet engine data is somewhere between the two), and what tradeoffs the business and IT teams are willing to make.
In an ideal world, we would tell you based on Dataiku’s hundreds of clients what this ideal balance is, and the challenge would be solved. But the reality is that to scale AI, IT managers need to conduct their own cost/benefit analysis and determine where on the sale is right for their specific scenario (this balance might even be different for different business units).
Deciding Which Technologies to Use
Innovation in IT and by IT teams is often more important to the scaling of AI than innovation in machine learning (ML) itself. That is, ultimately, most business problems won’t be solved by the latest, greatest, and fanciest ML techniques (like deep learning or neural networks), but rather by relatively classic techniques applied in smart ways to solve business issues. However, which technologies IT chooses for data processing, storage, etc., can make a big difference in the speed at which teams can execute on AI initiatives.
That being said, it’s important for IT managers to embrace innovations and new technologies, but at the same time, to be very selective about which technologies they choose. Having a deep understanding of what the business is trying to achieve versus what the trendy technologies are made for (and what they can — or can’t — do) is critical.
And while making innovative choices in technology could be the key to scaling AI, IT managers also need to be reasonable. Jumping on every new technology under the sun can be confusing for those trying to develop consistent processes and systems for AI (even with an abstraction layer, e.g., AI platforms like Dataiku, on top).
Whether to Buy End-to-End or Stitch Together Best-of-Breed Tools
Today, most organizations won’t consider fully building an AI platform solution. One of the biggest reasons is because of the hidden technical debt in ML systems identified by Google, which illustrates the sheer complexity of the endeavor. In other words, there is so much “glue” — so many features that are outside the core functionality of simply building an ML model — that building all of them from scratch to have an AI platform that truly allows for the scaling of AI efforts is prohibitively challenging.
Building a modern AI platform (and therefore scaling an enterprise-wide AI strategy) for most organizations today boils down to two options:
- Buying one end-to-end platform for data science, ML, and AI that covers the entire lifecycle, from the ingestion of raw data to ETL, building models to operationalization of those models and AI systems, plus the monitoring and governance of those systems.
- Buying best-of-breed tools for each of the steps or parts of the lifecycle and stitching together these tools to build the overall platform that is more customized for the organization and its needs.
Note that in many cases, the second option is situational, meaning it’s dictated by existing investments (i.e., we already have tools for x, y, and z, what can we add to complete the stack and how can we tie it all together?) rather than driven by explicit choice in making new investments that are the best fit for the organization’s needs.
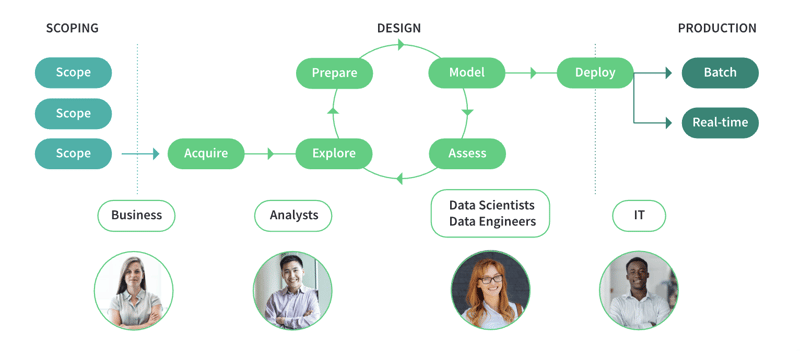
A representation of the data science, ML, and AI project lifecycle
Providing the very best tool for ETL, the very best for AutoML, for deploying to production, etc., will allow each team to choose the technology they want to work with, which is a tempting prospect when attempting to keep everyone happy — getting consciences across an organization is, admittedly, no easy task. However, the “glue” between these components, while not as complex as building everything from scratch, remains a huge challenge.
Besides the glue problem, there are also important components of the end-to-end lifecycle that are lost when moving from tool to tool. For example:
- Data lineage is difficult to track across tools. This is problematic for all organizations across industries, as visibility and explainability in AI processes are crucial to building trust both internally and externally in these systems (and for some highly regulated industries like financial services or pharmaceuticals, it’s required by law). With option two as outlined above, it will be difficult if not impossible to see at a glance which data is being used in what models, how that data is being treated, and which of those models using the data are in production vs. being used internally.
- Stitching together best-of-breed tools can also complexify the handoff between teams (for example, between analysts and data scientists following data cleansing, or between data scientists and IT or software engineers for deployment to production). Moving projects from tool to tool means some critical information might be lost, not to mention the handoff can take longer, slowing down the entire data-to-insights process.
- As a follow up to team handoffs and collaboration between data practitioners, another challenge is the pain of managing approval chains between tools. How can the business reduce risk by ensuring that there are checks and sign-offs when AI projects pass from one stage to the next, looking for issues with model bias, fairness, data privacy, etc.?
- Option two also means missed opportunities for automation between steps in the lifecycle, like triggering automated actions when the underlying data of a model or AI system in production has fundamentally changed.
- In the same vein, how do teams audit and version the various artifacts between all these tools? For instance, how does one know which version of the data pipeline in tool A matches with which model version in tool B for the whole system to work as expected?
Given the aforementioned challenges, the energy organizations put into building a modern AI platform shouldn’t be spent cobbling together tools across the lifecycle, which ultimately results in losing the larger picture of the full data pipeline (not to mention adds technical debt). Instead, investing in an end-to-end platform for AI (like Dataiku) provides cost savings via reuse, the ability to focus on implementing high-impact technologies, smooth governance and monitoring, and more.
Of course, the fear that comes with investing in one end-to-end platform is that the organization becomes tied to a single vendor. This isn’t a small risk and is not to be overlooked — lock in is a real consideration, as the company becomes dependent on that vendor’s roadmap, decisions, and more.
To that end, it’s important to invest in end-to-end technology that is open and extensible, allowing organizations to leverage existing underlying data architecture as well as invest in best-of-breed technologies in terms of storage, compute, algorithms, languages, frameworks, etc.