Stochastic Gradient Boosting: Choosing the Best Number of Iterations
Data Science and Beyond
DECEMBER 28, 2014
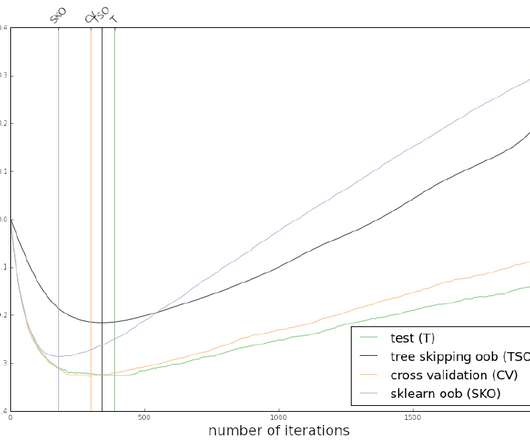
In my summary of the Kaggle bulldozer price forecasting competition, I mentioned that part of my solution was based on stochastic gradient boosting. To reduce runtime, the number of boosting iterations was set by minimising the loss on the out-of-bag (OOB) samples, skipping trees where samples are in-bag. This approach was motivated by a bug in scikit-learn, where the OOB loss estimate was calculated on the in-bag samples, meaning that it always improved (and thus was useless for the purpose of








Let's personalize your content