AWS Big Data Blog
Enable metric-based and scheduled scaling for Amazon Managed Service for Apache Flink
Thousands of developers use Apache Flink to build streaming applications to transform and analyze data in real time. Apache Flink is an open source framework and engine for processing data streams. It’s highly available and scalable, delivering high throughput and low latency for the most demanding stream-processing applications. Monitoring and scaling your applications is critical to keep your applications running successfully in a production environment.
Amazon Managed Service for Apache Flink is a fully managed service that reduces the complexity of building and managing Apache Flink applications. Amazon Managed Service for Apache Flink manages the underlying Apache Flink components that provide durable application state, metrics, logs, and more.
In this post, we show a simplified way to automatically scale up and down the number of KPUs (Kinesis Processing Units; 1 KPU is 1 vCPU and 4 GB of memory) of your Apache Flink applications with Amazon Managed Service for Apache Flink. We show you how to scale by using metrics such as CPU, memory, backpressure, or any custom metric of your choice. Additionally, we show how to perform scheduled scaling, allowing you to adjust your application’s capacity at specific times, particularly when dealing with predictable workloads. We also share an AWS CloudFormation utility to help you implement auto scaling quickly with your Amazon Managed Service for Apache Flink applications.
Metric-based scaling
This section describes how to implement a scaling solution for Amazon Managed Service for Apache Flink based on Amazon CloudWatch metrics. Amazon Managed Service for Apache Flink comes with an auto scaling option out of the box that scales out when container CPU utilization is above 75% for 15 minutes. This works well for many use cases; however, for some applications, you may need to scale based on a different metric, or trigger the scaling action at a certain point in time or by a different factor. You can customize your scaling policies and save costs by right-sizing your Amazon Managed Apache Flink applications by deploying this utility.
To perform metric-based scaling, we use CloudWatch alarms, Amazon EventBridge, AWS Step Functions, and AWS Lambda. You can choose from metrics coming from the source such as Amazon Kinesis Data Streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK), or metrics from the Amazon Managed Service for Apache Flink application. You can find these components in the CloudFormation template in the GitHub repo.
The following diagram shows how to scale an Amazon Managed Service for Apache Flink application in response to a CloudWatch alarm.

This solution uses the metric selected and creates two CloudWatch alarms that, depending on the threshold you use, trigger a rule in EventBridge to start running a Step Functions state machine. The following diagram illustrates the state machine workflow.
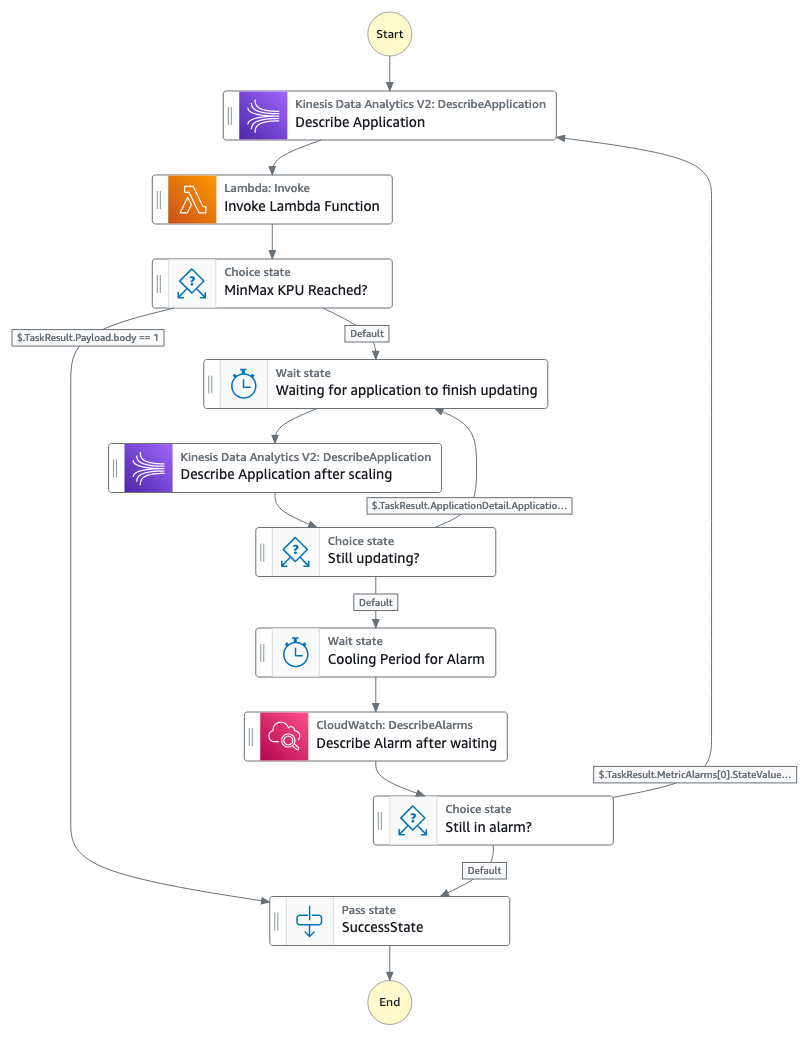
Note: Amazon Kinesis Data Analytics was renamed to Amazon Managed Service for Apache Flink August 2023
The Step Functions workflow consists of the following steps:
- The state machine describes the Amazon Managed Service for Apache Flink application, which will provide information related to the current number of KPUs in the application, as well if the application is being updated or is it running.
- The state machine invokes a Lambda function that, depending on which alarm was triggered, will scale the application up or down, following the parameters set in the CloudFormation template. When scaling the application, it will use the increase factor (either add/subtract or multiple/divide based on that factor) defined in the CloudFormation template. You can have different factors for scaling in or out. If you want to take a more cautious approach to scaling, you can use add/subtract and use an increase factor for scaling in/out of 1.
- If the application has reached the maximum or minimum number of KPUs set in the parameters of the CloudFormation template, the workflow stops. Keep in mind that Amazon Managed Service for Apache Flink applications have a default maximum of 64 KPUs (you can request to increase this limit). Do not specify a maximum value above 64 KPUs if you have not requested to increase the quota, because the scaling solution will get stuck by failing to update.
- If the workflow continues, because the allocated KPUs haven’t reached the maximum or minimum values, the workflow will wait for a period of time you specify, and then describe the application and see if it has finished updating.
- The workflow will continue to wait until the application has finished updating. When the application is updated, the workflow will wait for a period of time you specify in the CloudFormation template, to allow the metric to fall within the threshold and have the CloudWatch rule change from ALARM state to OK.
- If the metric is still in ALARM state, the workflow will start again and continue to scale the application either up or down. If the metric is in OK state, the workflow will stop.
For applications that read from a Kinesis Data Streams source, you can use the metric millisBehindLatest. If using a Kafka source, you can use records lag max for scaling events. These metrics capture how far behind your application is from the head of the stream. You can also use a custom metric that you have registered in your Apache Flink applications.
The sample CloudFormation template allows you to select one of the following metrics:
- Amazon Managed Service for Apache Flink application metrics – Requires an application name:
- ContainerCPUUtilization – Overall percentage of CPU utilization across task manager containers in the Flink application cluster.
- ContainerMemoryUtilization – Overall percentage of memory utilization across task manager containers in the Flink application cluster.
- BusyTimeMsPerSecond – Time in milliseconds the application is busy (neither idle nor back pressured) per second.
- BackPressuredTimeMsPerSecond – Time in milliseconds the application is back pressured per second.
- LastCheckpointDuration – Time in milliseconds it took to complete the last checkpoint.
- Kinesis Data Streams metrics – Requires the data stream name:
- MillisBehindLatest – The number of milliseconds the consumer is behind the head of the stream, indicating how far behind the current time the consumer is.
- IncomingRecords – The number of records successfully put to the Kinesis data stream over the specified time period. If no records are coming, this metric will be null and you won’t be able to scale down.
- Amazon MSK metrics – Requires the cluster name, topic name, and consumer group name):
- MaxOffsetLag – The maximum offset lag across all partitions in a topic.
- SumOffsetLag – The aggregated offset lag for all the partitions in a topic.
- EstimatedMaxTimeLag – The time estimate (in seconds) to drain MaxOffsetLag.
- Custom metrics – Metrics you can define as part of your Apache Flink applications. Most common metrics are counters (continuously increase) or gauges (can be updated with last value). For this solution, you need to add the kinesisAnalytics dimension to the metric group. You also need to provide the custom metric name as a parameter in the CloudFormation template. If you need to use more dimensions in your custom metric, you need to modify the CloudWatch alarm so it’s able to use your specific metric. For more information on custom metrics, see Using Custom Metrics with Amazon Managed Service for Apache Flink.
The CloudFormation template deploys the resources as well as the auto scaling code. You only need to specify the name of the Amazon Managed Service for Apache Flink application, the metric to which you want to scale your application in or out, and the thresholds for triggering an alarm. The solution by default will use the average aggregation for metrics and a period duration of 60 seconds for each data point. You can configure the evaluation periods and data points to alarm when defining the CloudFormation template.
Scheduled scaling
This section describes how to implement a scaling solution for Amazon Managed Service for Apache Flink based on a schedule. To perform scheduled scaling, we use EventBridge and Lambda, as illustrated in the following figure.

These components are available in the CloudFormation template in the GitHub repo.
The EventBridge scheduler is triggered based on the parameters set when deploying the CloudFormation template. You define the KPU of the applications when running at peak times, as well as the KPU for non-peak times. The application runs with those KPU parameters depending on the time of day.
As with the previous example for metric-based scaling, the CloudFormation template deploys the resources and scaling code required. You only need to specify the name of the Amazon Managed Service for Apache Flink application and the schedule for the scaler to modify the application to the set number of KPUs.
Considerations for scaling Flink applications using metric-based or scheduled scaling
Be aware of the following when considering these solutions:
- When scaling Amazon Managed Service for Apache Flink applications in or out, you can choose to either increase the overall application parallelism or modify the parallelism per KPU. The latter allows you to set the number of parallel tasks that can be scheduled per KPU. This sample only updates the overall parallelism, not the parallelism per KPU.
- If SnapshotsEnabled is set to true in ApplicationSnapshotConfiguration, Amazon Managed Service for Apache Flink will automatically pause the application, take a snapshot, and then restore the application with the updated configuration whenever it is updated or scaled. This process may result in downtime for the application, depending on the state size, but there will be no data loss. When using metric-based scaling, you have to choose a minimum and a maximum threshold of KPU the application can have. Depending on by how much you perform the scaling, if the new desired KPU is bigger or lower than your thresholds, the solution will update the KPUs to be equal to your thresholds.
- When using metric-based scaling, you also have to choose a cooling down period. This is the amount of time you want your application to wait after being updated, to see if the metric has gone from ALARM status to OK status. This value depends on how long are you willing to wait before another scaling event to occur.
- With the metric-based scaling solution, you are limited to choosing the metrics that are listed in the CloudFormation template. However, you can modify the alarms to use any available metric in CloudWatch.
- If your application is required to run without interruptions for periods of time, we recommend using scheduled scaling, to limit scaling to non-critical times.
Summary
In this post, we covered how you can enable custom scaling for Amazon Managed Service for Apache Flink applications using enhanced monitoring features from CloudWatch integrated with Step Functions and Lambda. We also showed how you can configure a schedule to scale an application using EventBridge. Both of these samples and many more can be found in the GitHub repo.
About the Authors
 Deepthi Mohan is a Principal PMT on the Amazon Managed Service for Apache Flink team.
Deepthi Mohan is a Principal PMT on the Amazon Managed Service for Apache Flink team.
 Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.