Improving the Performance of Multi-lingual Translation Models
This article was published as a part of the Data Science Blogathon.
 Source: Canva|Arxiv
Source: Canva|ArxivIntroduction
Conventionally, the method of training the Multilingual Neural Machine Translation (MNMT) model includes introducing an additional input tag at the encoder to indicate the target language, while the decoder employs the standard begin-of-sentence (BOS) token. The researchers from Microsoft have proposed a simple yet effective method for improving the direct (X-to-Y) translation in both zero-shot and instances where direct data is available. The method includes modifying the input tokens at the encoder and decoder. The source and target tokens are augmented to the input at the encoder side, and the target tokens are added at the decoder side, ie. the input tokens are modified to ST-T instead of T-B. This approach results in performance gain while training the model from scratch or fine-tuning a pre-trained model.
Now, let’s dive in and find out how this straightforward yet very effective approach can improve the performance of the multilingual translation model.
Highlights
1. The input tokens at the encoder and decoder are modified to include signals for source, and target languages, i.e., the input tokens are changed to ST-T instead of T-B.
2. Using the proposed tokens, the performance gain is noted while training from scratch or fine-tuning a pre-trained model.
3. For the WMT-based setting, zero-shot direct translation improved by ~1.3 BLEU points, and when direct data was used for training, there was ~0.4 BLEU point gain. In both instances, the English-centric performance was improved by ~3.97 in WMT21.
4. In the low-resource setting, a 1.5 ∼1.7 point gain was noted when finetuning on X-to-Y domain data.
5. In the medium-resource setting, the best strategy is to train the model using English-centric data, then add the direct data. It may need a smaller X ⇔Y dataset (fewer steps) in the two-phase setup than when using direct data from the start.
What’s the need for Direct Translation?
Language Models are trained with a large amount of data, typically consisting of millions of sentences carefully matched between the source and target languages. Datasets for commonly used language pairings, such as English and Spanish, are readily available, but what about, say Czech and some less-known African languages?
Most of the models/datasets are English-centric, and there aren’t large volumes of parallel sentences available for Czech and some languages. And this fact holds for many other different sources and target languages. Due to this constraint, conventionally, the translation is done from the source language to the target language pivoting through a common intermediary language (ex., English).
However, when we use an intermediary language for translation, we can easily detect marked changes in sentiment carried by the text and context changes. And this is common even when we are translating text from a high-resource language like the Spanish language to English. Imagine how much the translation accuracy will suffer when translating from a low-resource source language to the target language using English as an intermediate. To navigate these challenges, there’s a dire need to devise solutions that can directly translate one language to another without requiring an intermediary language.
Method Overview
The classic approach of training the Multilingual Neural Machine Translation (MNMT) model entails introducing an additional input tag at the encoder to indicate the target language. At the same time, the decoder employs the standard begin-of-sentence (BOS) token.
In the proposed technique, the input tokens at the encoder and decoder are modified to include signals for source and target languages, i.e. the input tokens are changed to ST-T instead of T-B (see Figure1). The encoder takes tokens for both the source and target languages (S, T), whereas the decoder takes a token only for the target language (T).

Figure 1: Illustration of the difference between the tokens (T-B) seen by the Encoder and decoder in the baseline (Left) and in the (Right) proposed method (ST-T)
It was noted that using the modified tokens enhances the performance on direct translation pairs without any parallel X ⇔Y translation data—training only on English-centric data (E ⇔X). Notably, impressive gains are achieved if we start with the model trained with baseline tokens and continue training after adding the new tokens. In the following experiments, some gains are still noticed when the baseline model is continued to train using a mix of direct (X ⇔Y) and English-centric training data, implying that the method is also applicable to non-zero-shot cases.
Experimental Setup
To validate the proposed method, the Transformer Encoder-Decoder architecture was used as a base model with 24 encoder layers, 12 decoder layers, 16 attention heads, pre-layer normalization, and RAdam optimizer for the experiments. Furthermore, the vocabulary of size 128,000 with Sentencepiece tokenizer is leveraged.
A model for 10 European languages was built using in-house data in preliminary experiments. Follow-up experiments used WMT data and other publicly available data spanning 6 languages. Moreover, most experiments employed English-centric training data, and some used direct training data or domain data.
Results
1. Medium-resource MNMT: Table 1 illustrates the SacreBLEU score of the base WMT model (first row) when finetuned in different setups, where a hooked arrow (→) indicates a row that continues training from the parent model.
i) First row: It indicates the scores of the base WMT model on both English-centric and direct dev sets (in zero-shot setting) with the T-B setup.
ii) Second row: Continuing to train the model (Row 1) using the new tokens yields gains on both dev sets, albeit less than expected from the preliminary results on EU10.
iii) Third row: Further continuing to train the base model with direct data yields impressive gains on the direct dev set but a lower gain on English-centric dev.
The third and last rows suggest that some gains from the new tokens after adding the direct data are still noticed. Out of all these strategies, the best strategy (row 3) is first to train the model using the English-centric data, then add the direct data. Also, Figure 2 suggests that it may need a smaller X ⇔Y dataset (fewer steps) in the two-phase setup than when using direct data from the start.
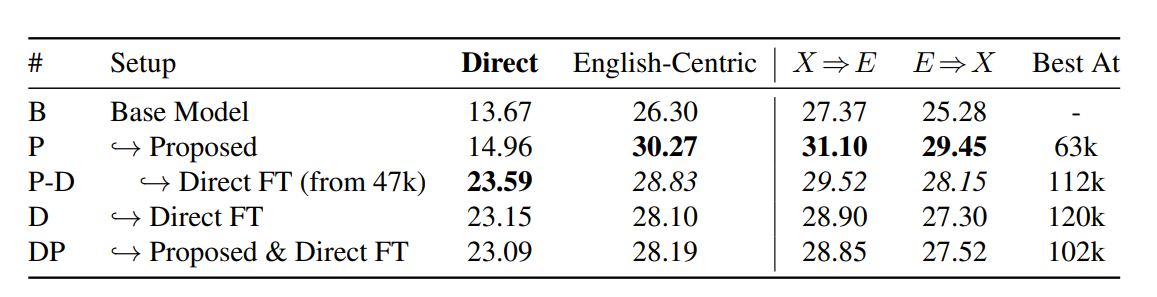
Table 1: SacreBLEU of the base WMT model (first row) when finetuned in various setups, where a hooked arrow (→) indicates a row that continues training from the parent model. (Source: Arxiv)
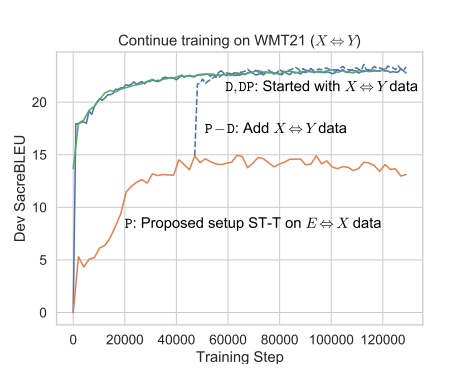
Figure 2: SacreBLEU for X ⇔Y dev set (Source: Arxiv)
2. Low-resource Adaptation: For the low-resource setting, a domain adaptation example is used. A separate WMT model is fine-tuned using the baseline and the proposed tokens for each adaptation experiment: for German to and from Czech, and for the domains EMEA, JRC, and Tanzil as attained from OPUS.
Table 2 suggests that the new tokens improve both the pre-trained and the fine-tuned models. The difference depends on the direction and the domain. This means one can start from an English-centric baseline and continue training using the new tokens to create a stronger base model that improves downstream performance for different directions and domains.
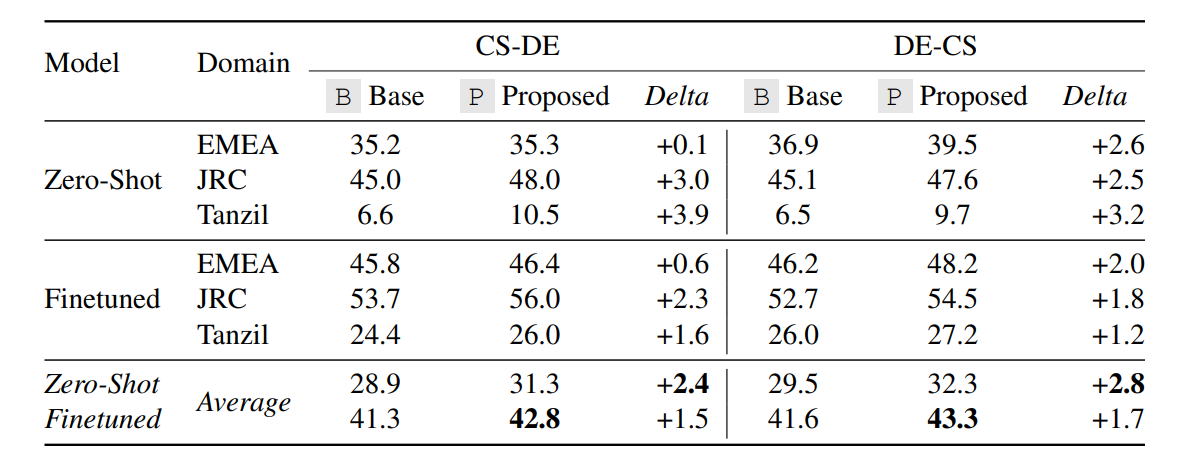
Table 2: Results of finetuning on different domains using proposed tokens and the baseline for
Czech ⇔ German. (Source: Arxiv)
Conclusion
To summarize, in this post, we learned the following:
1. The input tokens at the encoder and decoder are modified to include signals for source and target languages, i.e. the input tokens are changed to ST-T instead of T-B. The encoder takes tokens for both the source and target languages (S, T), while the decoder takes a token only for the target language (T).
2. The new input tokens at the encoder and decoder improve the direct translation for both zero-shot cases and cases where direct data is available.
3. For the WMT-based setting, zero-shot direct translation improved by ~1.3 BLEU points, and when direct data was used for training, there was ~0.4 BLEU point gain. In both cases, the English-centric performance was also increased by ~3.97 in WMT21. COMET scores increased by 2.56 points on X ⇔Y dev, and 15.23 points on E ⇒ X dev.
4. In the low-resource setting, a 1.5 ∼1.7 point gain was noticed when finetuning on X-to-Y domain data. In the medium-resource setting, the best strategy is first to train the model using English-centric data, then add the direct data. It was also noted that it might need a smaller X ⇔Y dataset (fewer steps) in the two-phase setup than when using direct data from the start.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







