How to Create a Pandas DataFrame from Lists ?
Introduction
Creating a Pandas DataFrame is a fundamental task in data analysis and manipulation. It allows us to organize and work with structured data efficiently. In this article, we will explore how to create a Pandas DataFrame from lists, discussing the reasons behind it and providing a step-by-step guide. By the end of this article, you will have a clear understanding of different methods, handling different data types, dealing with missing values, and advanced techniques for creating DataFrames from lists.
Join our complimentary Python course to deepen your understanding.

Table of contents
- What is a Pandas DataFrame?
- Why Create a DataFrame from Lists?
- Overview of the Process
- Creating a Pandas DataFrame from Lists
- Alternative Methods for Creating a DataFrame from Lists
- Handling Different Data Types in Lists
- Dealing with Missing Values in Lists
- Advanced Techniques for Creating DataFrames from Lists
- Frequently Asked Questions
What is a Pandas DataFrame?
Before diving into the process of creating a DataFrame from lists, let’s briefly understand what a Pandas DataFrame is. In simple terms, a DataFrame is a two-dimensional labeled data structure with columns of potentially different types. It is similar to a table in a relational database or a spreadsheet in Excel. DataFrames provide a powerful and flexible way to analyze, manipulate, and visualize data.
Why Create a DataFrame from Lists?
Creating a DataFrame from lists is a common requirement in data analysis and data science projects. Lists are a versatile data structure in Python, and often we have data stored in lists that we want to convert into a DataFrame for further analysis. By converting lists into a DataFrame, we can leverage the extensive functionality provided by Pandas to perform various operations on the data, such as filtering, sorting, aggregating, and visualizing.

Overview of the Process
The process of creating a Pandas DataFrame from lists involves several steps. Here is an overview of the process:
1. Importing the Pandas Library: Before we can create a DataFrame, we need to import the Pandas library. This can be done using the `import pandas as pd` statement.
2. Creating Lists for Each Column: We need to create separate lists for each column of the DataFrame. Each list represents the values for a specific column.
3. Combining Lists into a Dictionary: We combine the lists into a dictionary, where the keys represent the column names and the values represent the corresponding lists.
4. Converting the Dictionary to a DataFrame: Finally, we convert the dictionary into a DataFrame using the `pd.DataFrame()` function or other alternative methods.
Creating a Pandas DataFrame from Lists
Now let’s dive into the detailed steps of creating a Pandas DataFrame from lists.
Importing the Pandas Library
To begin, we need to import the Pandas library. This can be done using the following code:
import pandas as pdCreating Lists for Each Column
Next, we create separate lists for each column of the DataFrame. For example, let’s say we have three columns: “Name,” “Age,” and “City.” We can create lists for each column as follows:
names = ["John", "Alice", "Bob"]
ages = [25, 30, 35]
cities = ["New York", "London", "Paris"]Combining Lists into a Dictionary
Once we have the lists for each column, we combine them into a dictionary. The keys of the dictionary represent the column names, and the values represent the corresponding lists. Here’s an example:
data = {
"Name": names,
"Age": ages,
"City": cities
}Converting the Dictionary to a DataFrame
Finally, we convert the dictionary into a DataFrame using the `pd.DataFrame()` function. Here’s how it can be done:
df = pd.DataFrame(data)
print(df)Output:


Alternative Methods for Creating a DataFrame from Lists
Apart from the method described above, there are alternative methods available for creating a DataFrame from lists. Let’s explore some of them:
Using the pd.DataFrame() Function
The `pd.DataFrame()` function can directly take lists as arguments and create a DataFrame. Here’s an example:
df = pd.DataFrame([names, ages, cities], columns=["Name", "Age", "City"])Using the from_dict() Method
The `from_dict()` method can be used to create a DataFrame from a dictionary. Here’s an example:
df = pd.DataFrame.from_dict(data)Using the zip() Function
The `zip()` function can be used to combine multiple lists into a list of tuples, which can then be converted into a DataFrame. Here’s an example:
data = list(zip(names, ages, cities))
df = pd.DataFrame(data, columns=["Name", "Age", "City"])Handling Different Data Types in Lists
Lists can contain different data types, such as numeric data, string data, or date and time data. Let’s explore how to create a DataFrame with different data types.
Creating a DataFrame with Numeric Data
If the lists contain numeric data, the resulting DataFrame will have the corresponding numeric data type. Here’s an example:
numbers = [1, 2, 3, 4, 5]
df = pd.DataFrame(numbers, columns=["Number"])Creating a DataFrame with String Data
If the lists contain string data, the resulting DataFrame will have the corresponding string data type. Here’s an example:
fruits = ["Apple", "Banana", "Orange"]
df = pd.DataFrame(fruits, columns=["Fruit"])Creating a DataFrame with Date and Time Data
If the lists contain date and time data, the resulting DataFrame will have the corresponding date and time data type. Here’s an example:
import datetime
dates = [
datetime.date(2022, 1, 1),
datetime.date(2022, 1, 2),
datetime.date(2022, 1, 3)
]
df = pd.DataFrame(dates, columns=["Date"])Dealing with Missing Values in Lists
Lists may contain missing values, represented as NaN, None, or a default value. Let’s explore how to handle missing values when creating a DataFrame.
Handling Missing Values with NaN
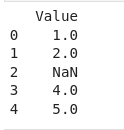
If a list contains missing values represented as NaN, Pandas will automatically handle them when creating a DataFrame. Here’s an example:
values = [1, 2, float("nan"), 4, 5]
df = pd.DataFrame(values, columns=["Value"])
print(df)Output:
In Python, float(“nan”) is used to represent NaN (Not a Number). When Pandas displays the DataFrame, it uses the standard representation for NaN values, which is “NaN”.
Handling Missing Values with None
If a list contains missing values represented as None, Pandas will automatically handle them when creating a DataFrame. Here’s an example:
values = [1, 2, None, 4, 5]
df = pd.DataFrame(values, columns=["Value"])Handling Missing Values with a Default Value
If a list contains missing values represented as a default value, we can replace them before creating a DataFrame. Here’s an example:
values = [1, 2, -1, 4, 5]
default_value = -1
values = [default_value if value == default_value else value for value in values]
df = pd.DataFrame(values, columns=["Value"])Advanced Techniques for Creating DataFrames from Lists
In addition to the basic methods, Pandas provides advanced techniques for creating DataFrames from lists. Let’s explore some of them:
Creating a Multi-index DataFrame
A multi-index DataFrame is a DataFrame with multiple levels of row and column indices. It can be created using the `pd.MultiIndex.from_arrays()` function. Here’s an example:
index = pd.MultiIndex.from_arrays([names, cities], names=["Name", "City"])
df = pd.DataFrame(data, index=index)Creating a DataFrame with Custom Column Names
By default, the column names of a DataFrame are derived from the keys of the dictionary or the list of column names. However, we can specify custom column names using the `columns` parameter. Here’s an example:
df = pd.DataFrame(data, columns=["Full Name", "Years", "Location"])Creating a DataFrame with Index Labels
We can assign index labels to the rows of a DataFrame using the `index` parameter. Here’s an example:
df = pd.DataFrame(data, index=["A", "B", "C"])Conclusion
In this article, we have explored how to create a Pandas DataFrame from lists. We have discussed the reasons behind creating a DataFrame from lists and provided a step-by-step guide. We have also covered alternative methods, handling different data types, dealing with missing values, and advanced techniques for creating DataFrames from lists.
By following the examples and code provided in this article, you can easily create DataFrames from lists and leverage the power of Pandas for data analysis and manipulation.
You can also refer to these articles to know more:
- How to Add a New Column to an Existing DataFrame in Pandas?
- Supercharge Your DataFrames: Mastering Row Appending in Pandas
- Unveiling 3 Powerful Techniques with Merge Pandas
Frequently Asked Questions
A: Creating a DataFrame from lists is a common practice in data analysis projects. Lists often store data that analysts want to convert into a DataFrame for further exploration. This conversion allows leveraging Pandas’ powerful functionality for operations like filtering, sorting, aggregating, and visualization.
A: The process involves importing the Pandas library, creating separate lists for each column, combining lists into a dictionary, and finally converting the dictionary into a DataFrame using the pd.DataFrame() function. Alternative methods and advanced techniques can also be employed.
A: Yes, lists can contain different data types, such as numeric data, string data, or date and time data. Pandas will automatically handle diverse data types when creating the DataFrame.
A: Pandas can handle missing values represented as NaN, None, or a default value. If your list contains NaN, Pandas will automatically recognize and handle it. If using None or a default value, you can replace or handle them before creating the DataFrame.
A: Yes, advanced techniques include creating a multi-index DataFrame, customizing column names, and assigning index labels to rows. These techniques provide more flexibility and control over the structure of the resulting DataFrame.








