
Understanding Simpson’s Paradox to Avoid Faulty Conclusions
Sisense
JANUARY 21, 2020
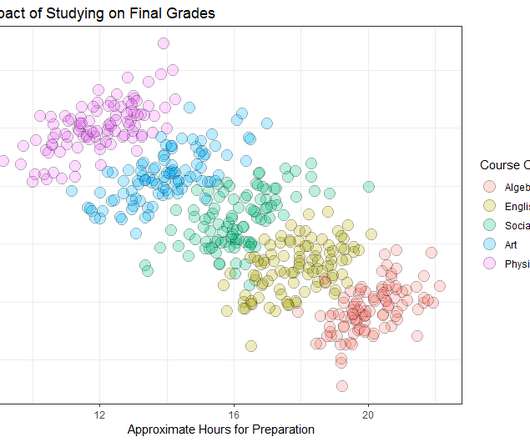
One of the simplest ways to start exploring your data is to aggregate the metrics you are interested in by their relevant dimensions. A new drug promising to reduce the risk of heart attack was tested with two groups. When the data is combined, it seems that the drug reduces the risk of getting a heart attack.












Let's personalize your content