
Build efficient, cross-Regional, I/O-intensive workloads with Dask on AWS
AWS Big Data
MAY 4, 2023
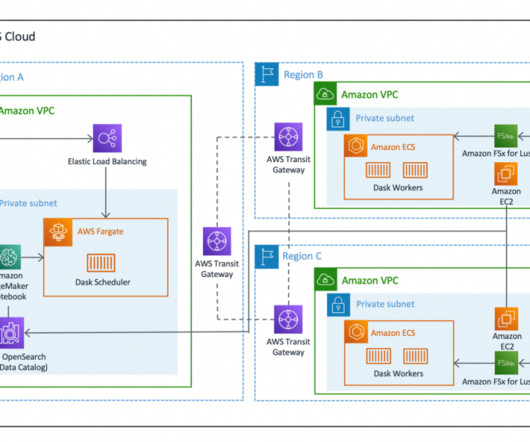
Dataset Variables Disk Size Xarray Dataset Size Region ERA5 2011–2020 (120 netcdf files) 53.5GB 364.1 Jupyter notebook As part of the solution launch, we deploy a preconfigured Jupyter notebook to help test the cross-Regional Dask solution. The following table summarizes our dataset details.








Let's personalize your content