

Power analytics as a service capabilities using Amazon Redshift
AWS Big Data
APRIL 17, 2024
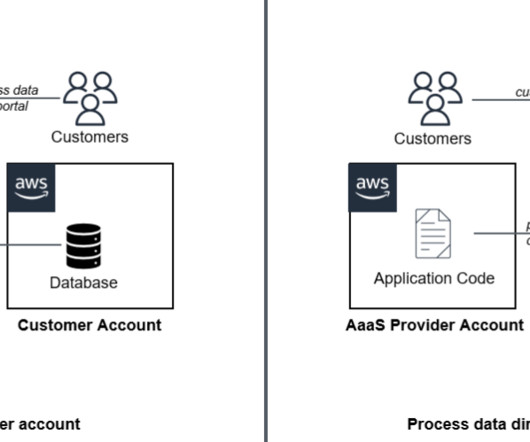
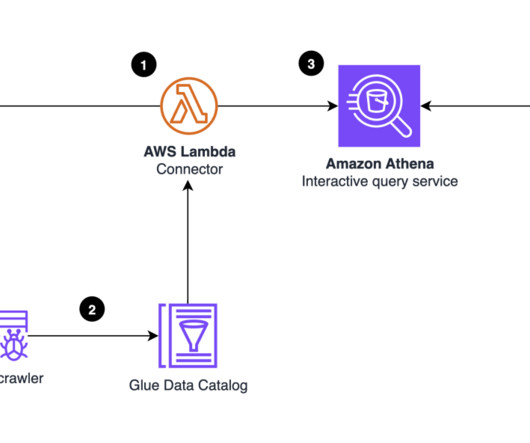
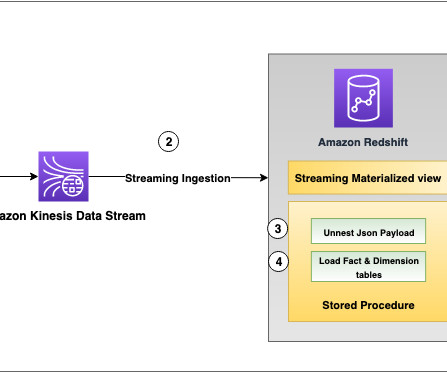
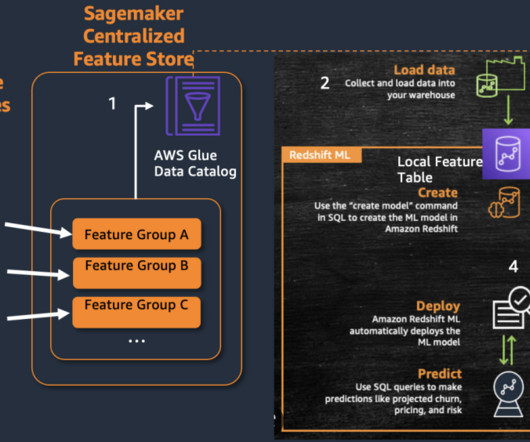
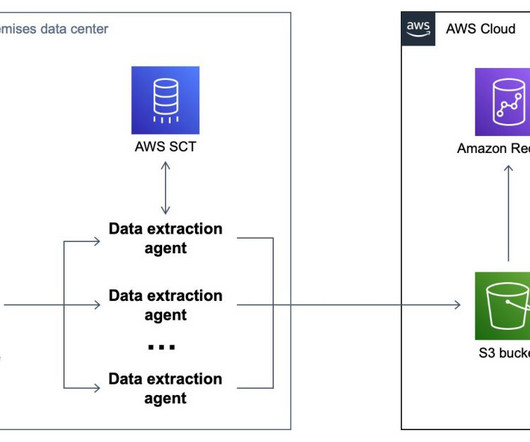
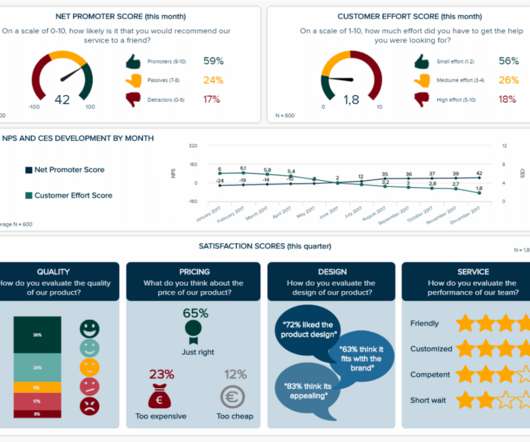
Amazon Redshift is a cloud data warehouse service that offers real-time insights and predictive analytics capabilities for analyzing data from terabytes to petabytes. For example, you can build visualizations on top of Amazon Redshift and embed them within applications to provide outstanding analytics experiences for end-users.









































Let's personalize your content