

Understanding The Value Of Column Charts With Examples & Templates
datapine
MARCH 21, 2023
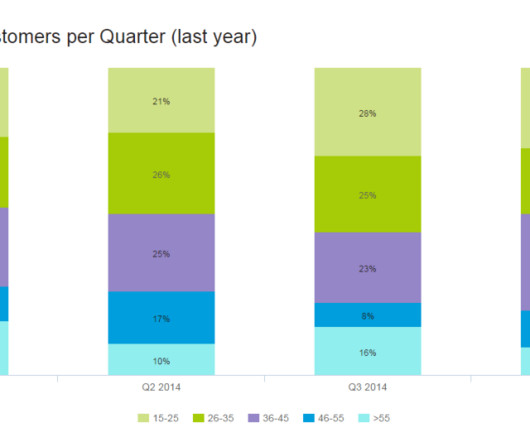
Table of Contents 1) What Are Column Charts & Graphs? 2) Pros & Cons Of Column Charts 3) When To Use A Column Graph 4) Types Of Column Charts 5) Column Graphs & Charts Best Practices 6) Column Chart Examples Data visualization has been a part of our lives for many many years now.









































Let's personalize your content