

Key Components and Challenges of Data Lakes
Analytics Vidhya
OCTOBER 4, 2022
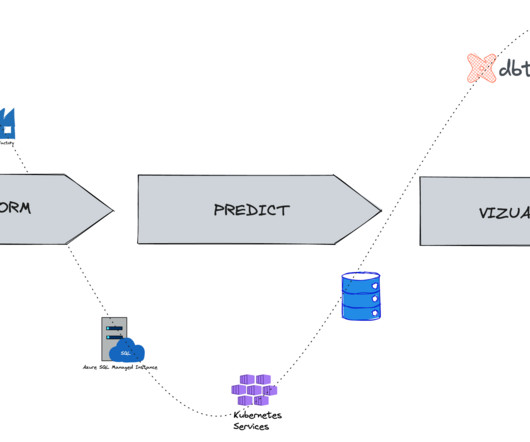
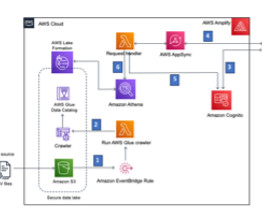
Introduction Today, Data Lake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy. An ecosystem consists of […].













































Let's personalize your content