

Important Considerations When Migrating to a Data Lake
Smart Data Collective
MARCH 30, 2022
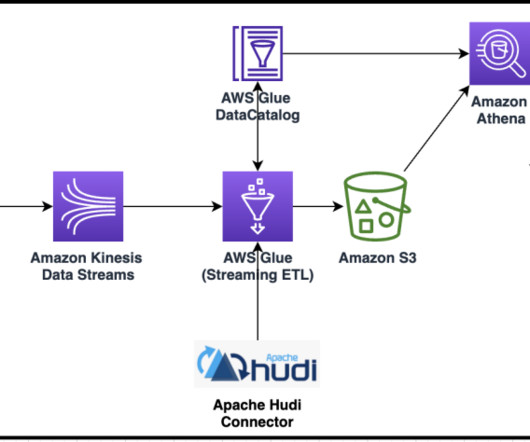
Azure Data Lake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between data lakes and data warehouses. Determine your preparedness.
































Let's personalize your content