
Use Snowflake with Amazon MWAA to orchestrate data pipelines
AWS Big Data
OCTOBER 31, 2023
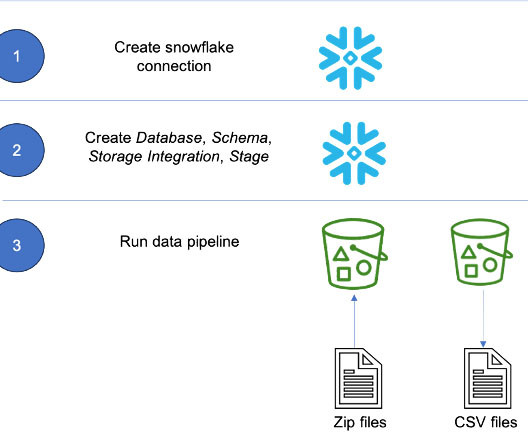
To create the connection string, the Snowflake host and account name is required. Using the worksheet, run the following SQL commands to find the host and account name. The account, host, user, password, and warehouse can differ based on your setup. Choose Next. For Secret name , enter airflow/connections/snowflake_accountadmin.











Let's personalize your content