

Orchestrate an end-to-end ETL pipeline using Amazon S3, AWS Glue, and Amazon Redshift Serverless with Amazon MWAA
AWS Big Data
APRIL 25, 2024
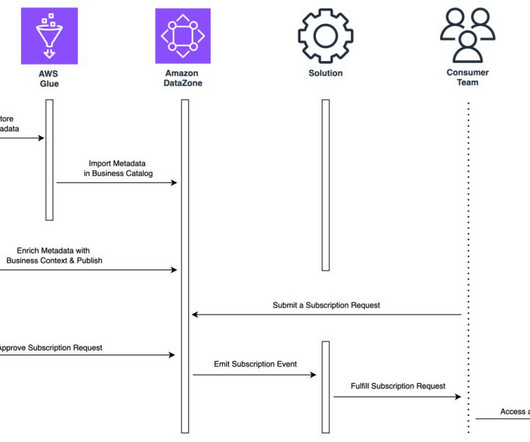
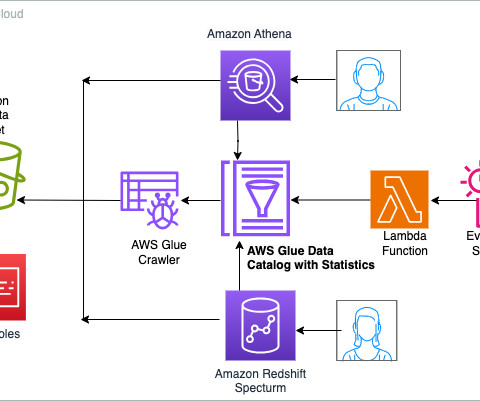
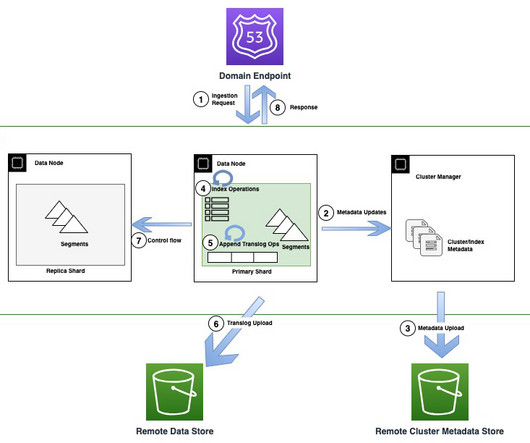
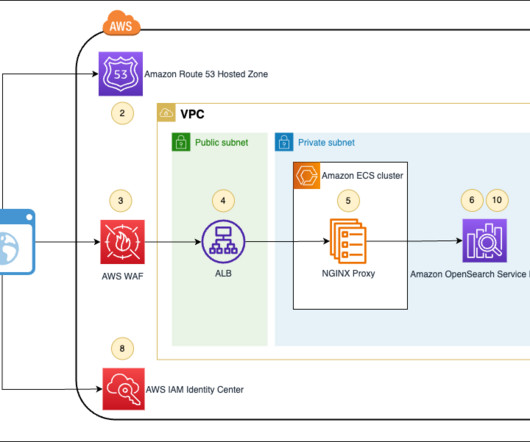
Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering. secretsmanager ). redshift-serverless.amazonaws.com:5439?










































Let's personalize your content