

Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
AWS Big Data
APRIL 24, 2023
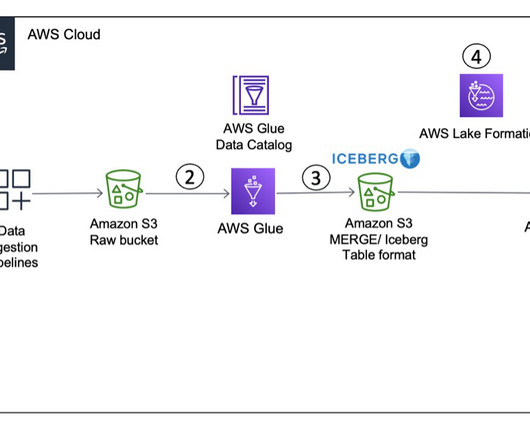
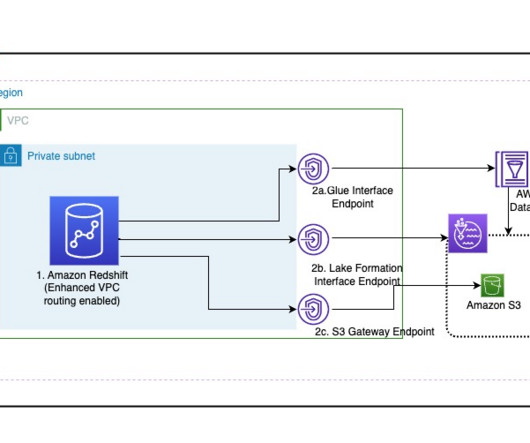
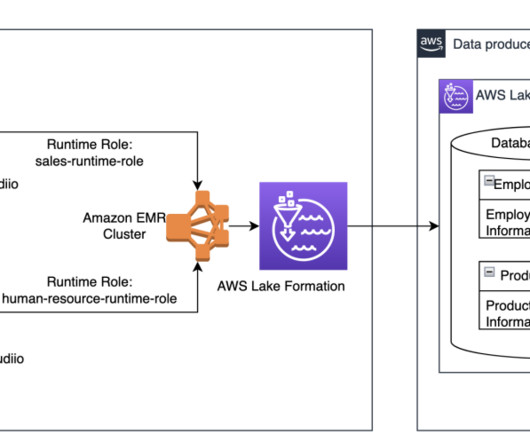
Solution overview To explain this setup, we present the following architecture, which integrates Amazon S3 for the data lake (Iceberg table format), Lake Formation for access control, AWS Glue for ETL (extract, transform, and load), and Athena for querying the latest inventory data from the Iceberg tables using standard SQL.













































Let's personalize your content