
Business Strategies for Deploying Disruptive Tech: Generative AI and ChatGPT
Rocket-Powered Data Science
FEBRUARY 15, 2023
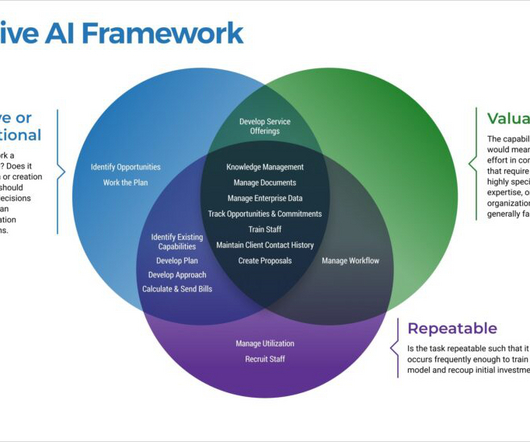
Those F’s are: Fragility, Friction, and FUD (Fear, Uncertainty, Doubt). encouraging and rewarding) a culture of experimentation across the organization. Keep it agile, with short design, develop, test, release, and feedback cycles: keep it lean, and build on incremental changes. Test early and often. Launch the chatbot.

















Let's personalize your content