

Understanding The Value Of Column Charts With Examples & Templates
datapine
MARCH 21, 2023
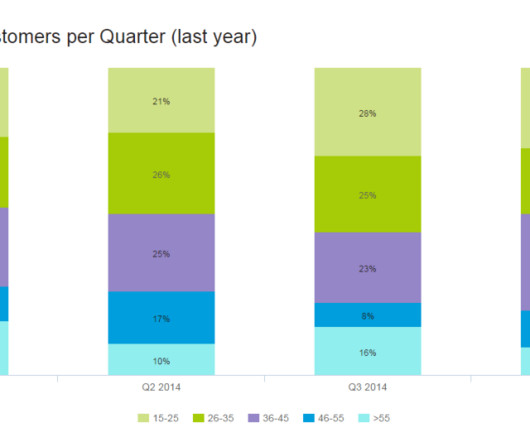
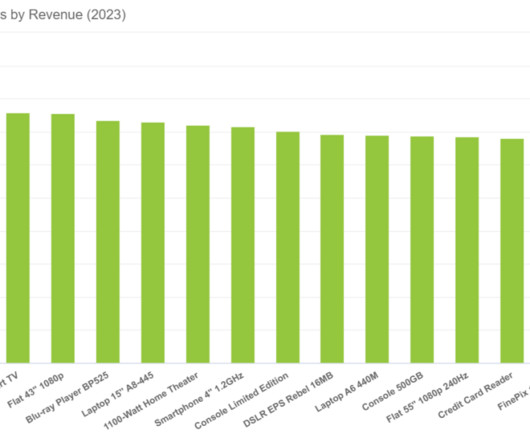
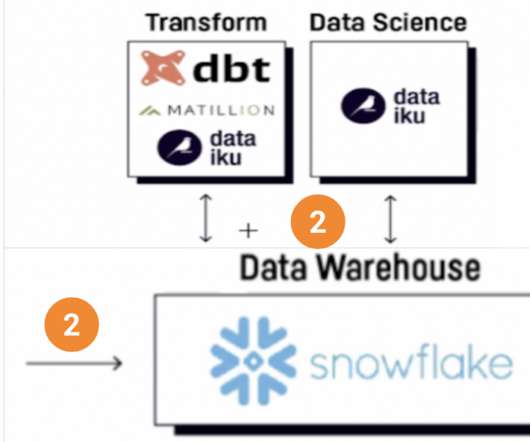
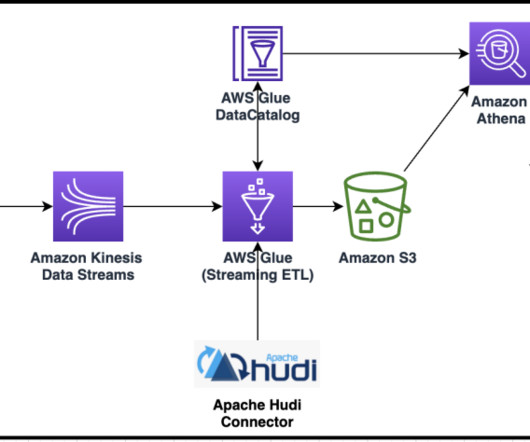
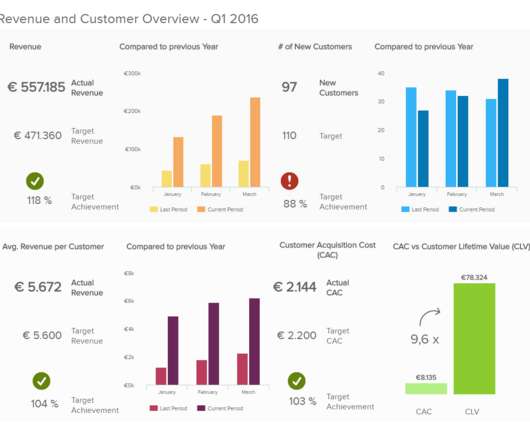
For that reason, it is important to know how to interpret graphs and charts and understand their uses in various contexts. To help you in that task, at datapine, we are putting together a series of blog posts that offer an in-depth look into different types of graphs and charts , teaching you when to use them through interactive examples.






































Let's personalize your content