
Migrate a petabyte-scale data warehouse from Actian Vectorwise to Amazon Redshift
AWS Big Data
MAY 30, 2024
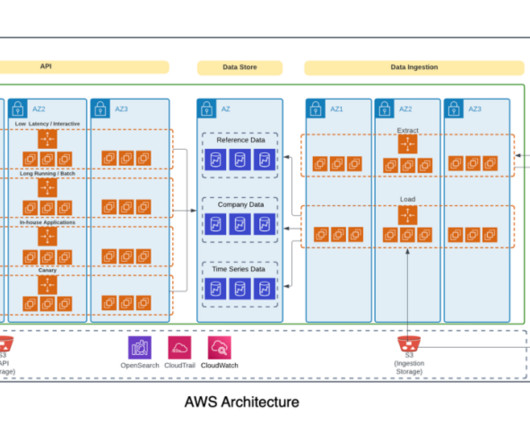
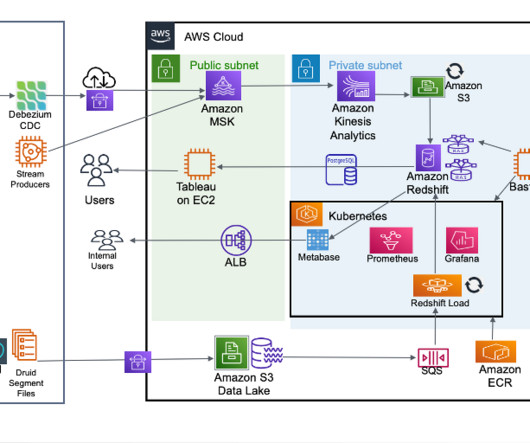
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Solution overview Amazon Redshift is an industry-leading cloud data warehouse.














































Let's personalize your content