

Choosing an open table format for your transactional data lake on AWS
AWS Big Data
JUNE 9, 2023
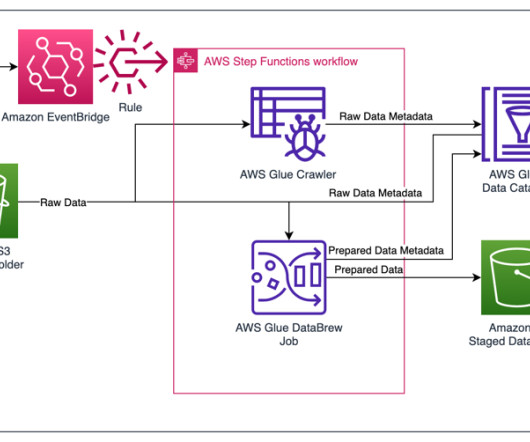
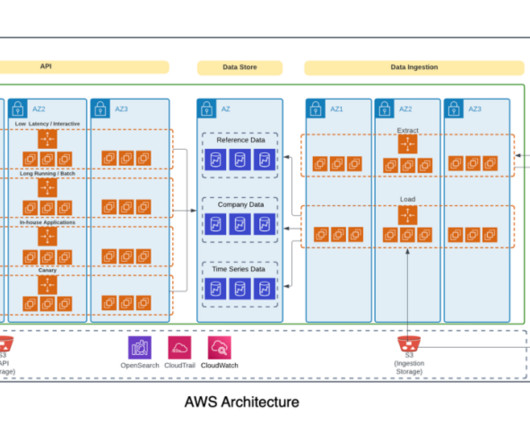
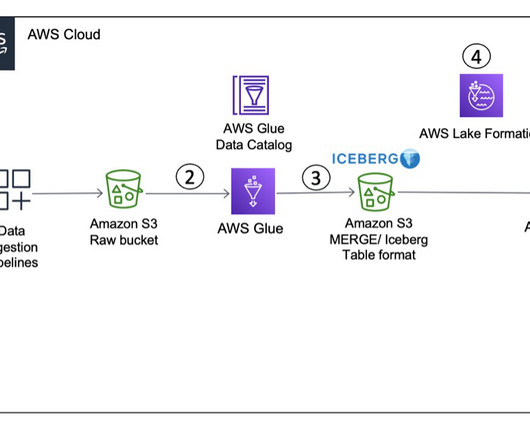
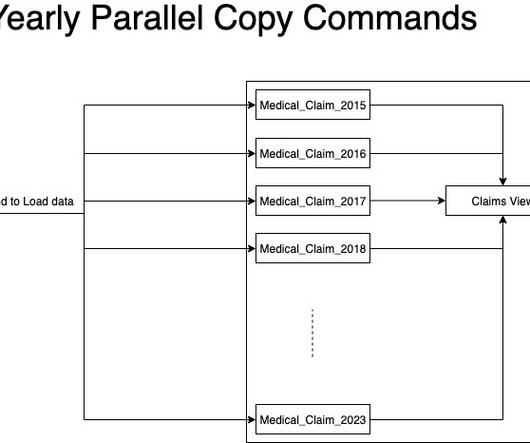
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale.













































Let's personalize your content