
Amazon OpenSearch Service Under the Hood : OpenSearch Optimized Instances(OR1)
AWS Big Data
APRIL 17, 2024
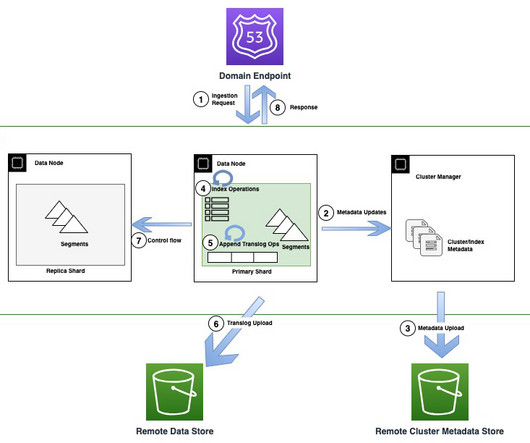
In order to provide these benefits, OpenSearch is designed as a high-scale distributed system with multiple independent instances indexing data and processing requests. Other customers require high durability and as a result need to maintain multiple replica copies, resulting in higher operating costs for them.




























Let's personalize your content