

Design a data mesh pattern for Amazon EMR-based data lakes using AWS Lake Formation with Hive metastore federation
AWS Big Data
JUNE 10, 2024
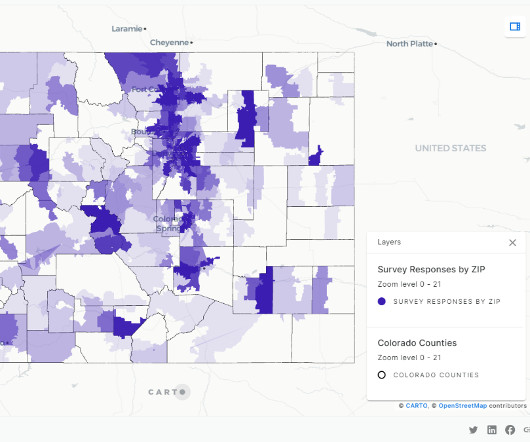
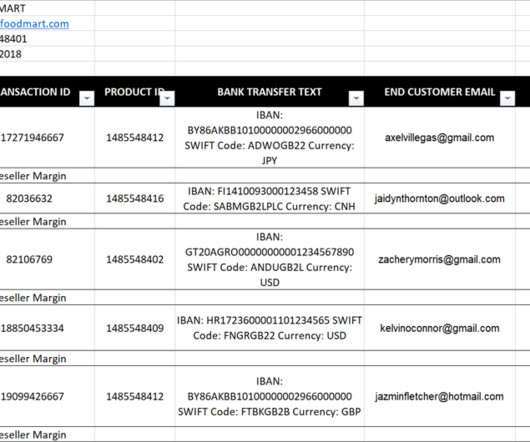
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. An entity can act both as a producer of data assets and as a consumer of data assets.














































Let's personalize your content