

What is a data architect? Skills, salaries, and how to become a data framework master
CIO Business Intelligence
OCTOBER 13, 2023
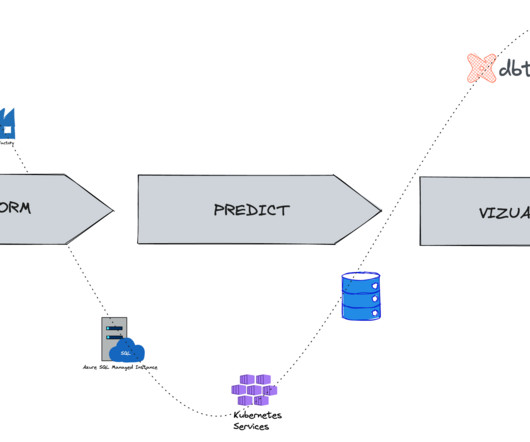
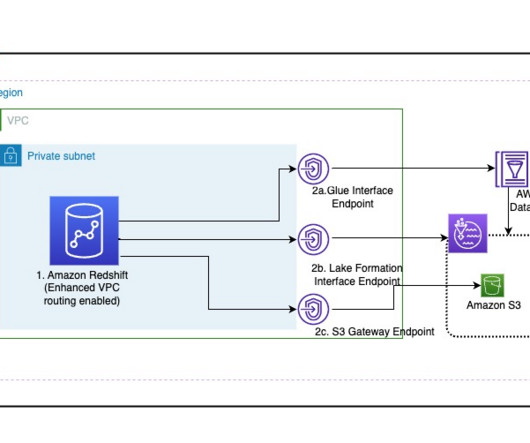
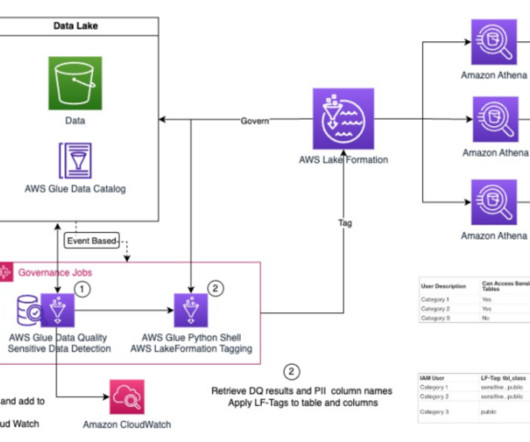
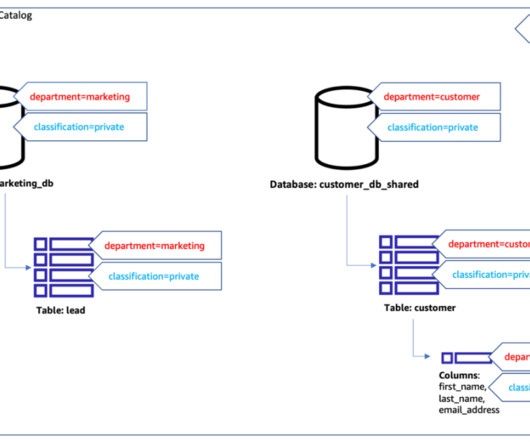
Data architecture is a complex and varied field and different organizations and industries have unique needs when it comes to their data architects. Solutions data architect: These individuals design and implement data solutions for specific business needs, including data warehouses, data marts, and data lakes.
























Let's personalize your content