
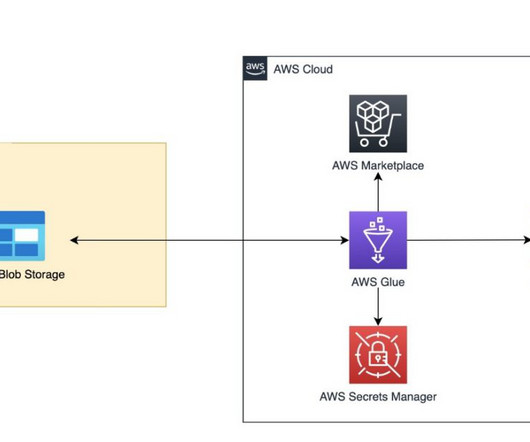
Migrate data from Azure Blob Storage to Amazon S3 using AWS Glue
AWS Big Data
OCTOBER 20, 2023
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Azure Data Lake Storage that allow you to move data bi-directionally between Azure Blob Storage, Azure Data Lake Storage, and Amazon Simple Storage Service (Amazon S3). option("header","true").load("wasbs://yourblob@youraccountname.blob.core.windows.net/loadingtest-input/100mb")






























Let's personalize your content