

Enable data analytics with Talend and Amazon Redshift Serverless
AWS Big Data
JULY 25, 2023
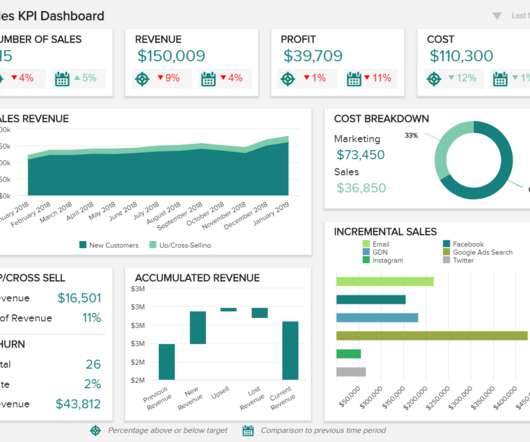
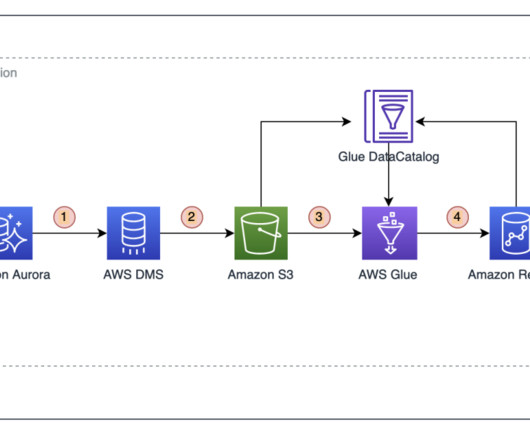
The integration of Talend Cloud and Talend Stitch with Amazon Redshift Serverless can help you achieve successful business outcomes without data warehouse infrastructure management. Data scientists, developers, and data analysts can access meaningful insights and build data-driven applications with zero maintenance.






































Let's personalize your content