

Implement alerts in Amazon OpenSearch Service with PagerDuty
AWS Big Data
JUNE 8, 2023
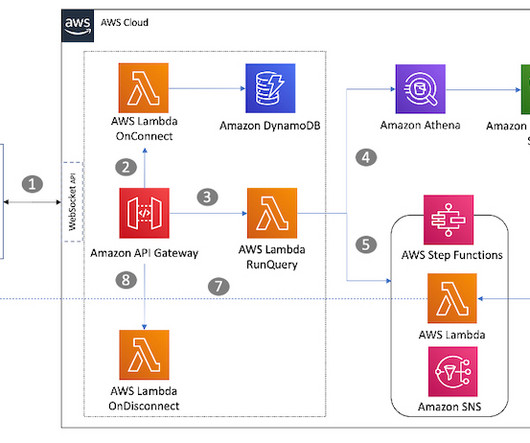
For instructions, refer to Creating and managing Amazon OpenSearch Service domains. For Host , enter events.PagerDuty.com. Choose Send test message and test to make sure you receive an alert on the PagerDuty service. This notification can be safely acknowledged and resolved from PagerDuty because this is was a test.



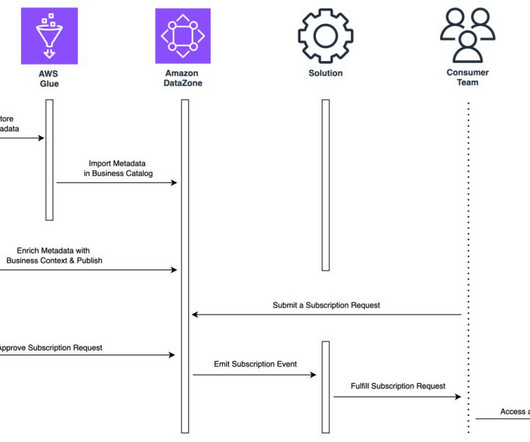
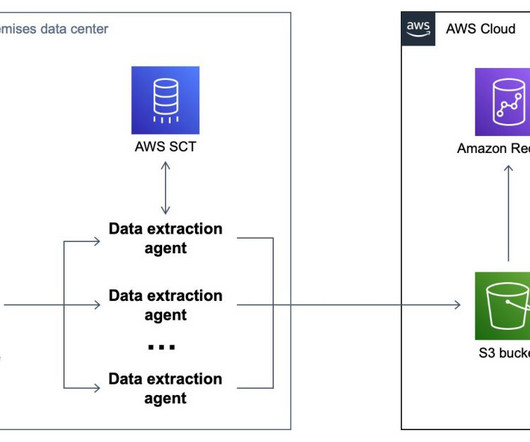

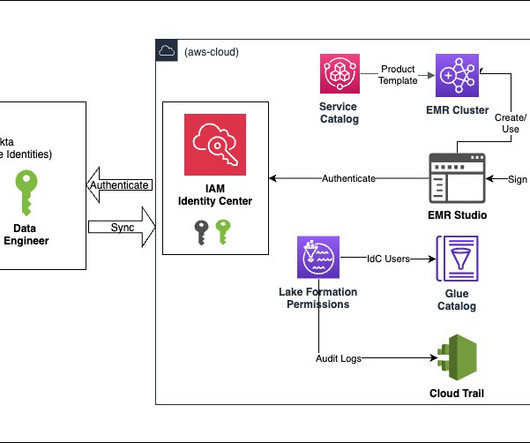
















Let's personalize your content