
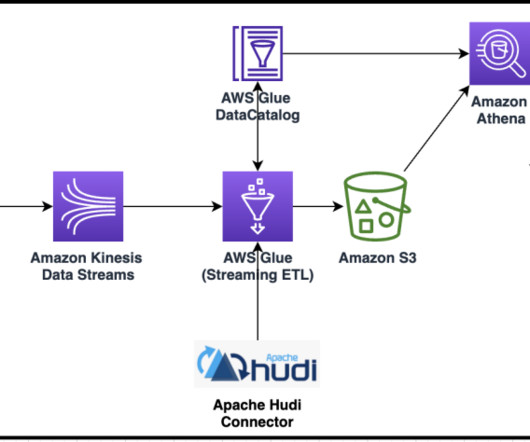
Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight
AWS Big Data
AUGUST 3, 2023
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with data lakes to have better scalability and performance. For more information, see Changing the default settings for your data lake.


















Let's personalize your content