
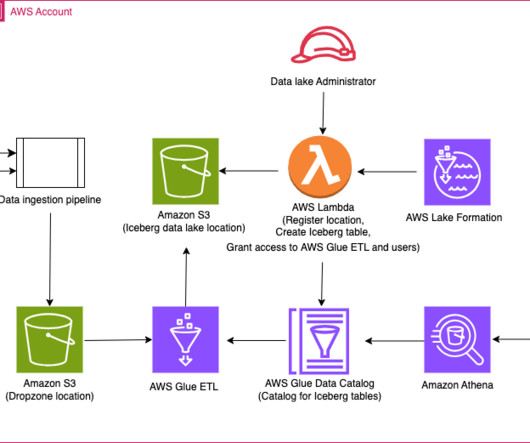
Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
AWS Big Data
MARCH 4, 2024
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. Schema evolution enables adding, deleting, renaming, or modifying columns without needing to rewrite existing data.



















Let's personalize your content