

Optimize write throughput for Amazon Kinesis Data Streams
AWS Big Data
JUNE 3, 2024
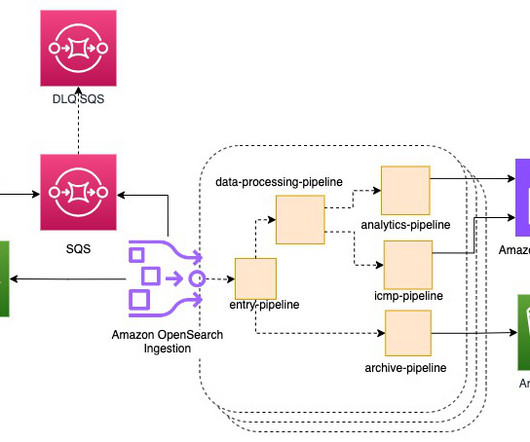
We then guide you on swift responses to these events and provide several solutions for mitigation. Imagine you have a fleet of web servers logging performance metrics for each web request served into a Kinesis data stream with two shards and you used a request URL as the partition key. Why do we get write throughput exceeded errors?














































Let's personalize your content