
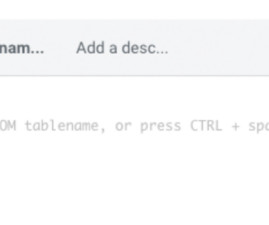
Setting up and Getting Started with Cloudera’s New SQL AI Assistant
Cloudera
JANUARY 19, 2024
As described in our recent blog post , an SQL AI Assistant has been integrated into Hue with the capability to leverage the power of large language models (LLMs) for a number of SQL tasks. Supported AI models and services The SQL AI Assistant is not bundled with a specific LLM; instead it supports various LLMs and hosting services.







































Let's personalize your content