
Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
AWS Big Data
NOVEMBER 9, 2023
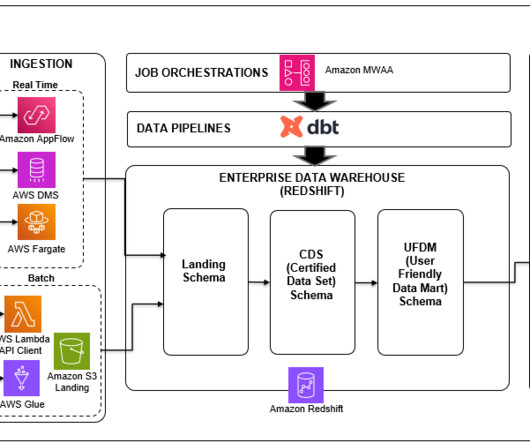
A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. It does this by helping teams handle the T in ETL (extract, transform, and load) processes.






















Let's personalize your content