

Simplify Metrics on Apache Druid With Rill Data and Cloudera
Cloudera
JULY 21, 2022
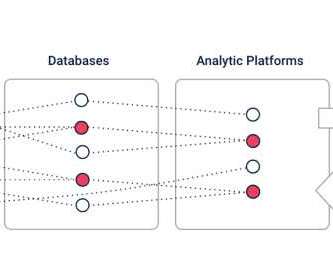
Co-author: Mike Godwin, Head of Marketing, Rill Data. Cloudera has partnered with Rill Data, an expert in metrics at any scale, as Cloudera’s preferred ISV partner to provide technical expertise and support services for Apache Druid customers. Deploying metrics shouldn’t be so hard. Cloudera Data Warehouse).












































Let's personalize your content