
Implement data warehousing solution using dbt on Amazon Redshift
AWS Big Data
NOVEMBER 17, 2023
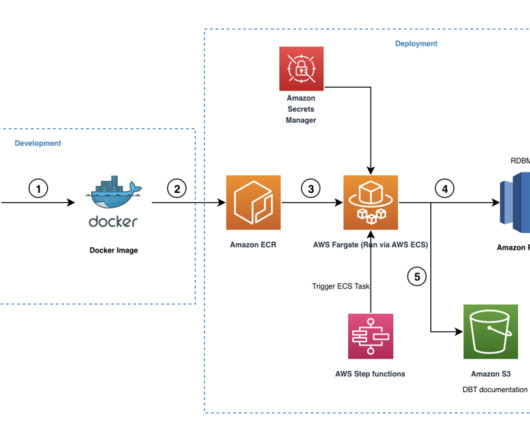
dbt (DataBuildTool) offers this mechanism by introducing a well-structured framework for data analysis, transformation and orchestration. It also applies general software engineering principles like integrating with git repositories, setting up DRYer code, adding functional test cases, and including external libraries.











































Let's personalize your content