

In-place version upgrades for applications on Amazon Managed Service for Apache Flink now supported
AWS Big Data
MAY 23, 2024
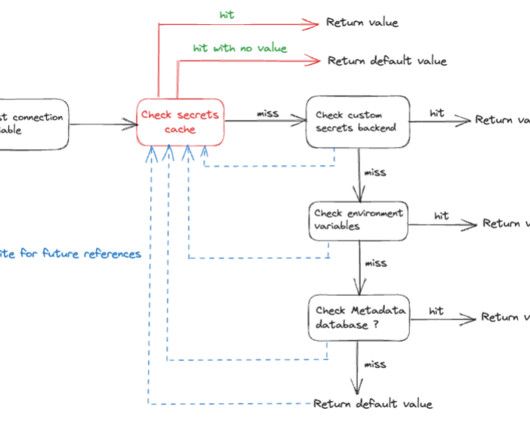
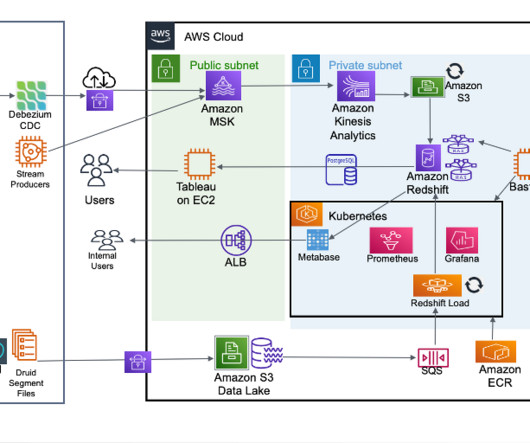
Apache Flink is an open source distributed processing engine, offering powerful programming interfaces for both stream and batch processing, with first-class support for stateful processing and event time semantics. Some things to keep in mind: Stateful downgrades are not compatible and will not be accepted due to snapshot incompatibility.











































Let's personalize your content