

Joining Datasets With Imprecise Data: The Benefits of Fuzzy Join Using a Fuzzy Matching Algorithm
Dataiku
OCTOBER 20, 2021
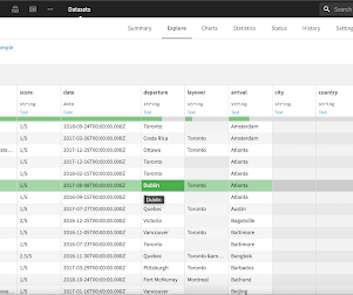
Imagine that you’re just about to buy a new shirt at your local big box retailer. “Do Do you have an account with us?” asks the cashier. You think you may have signed up before, but can’t really remember.
















Let's personalize your content